Deep Voice 3
论文信息
- 发表机构:Baidu
- 发表时间:2017-10
- 论文链接:https://arxiv.org/pdf/1710.07654.pdf
简介
本文提出了一个全卷积架构的语音合成框架
特别地,本文的贡献包括:
- 提出了全卷积的字符到频谱的架构,能够在序列上完成并行计算,训练速度比采用循环单元的类似架构快一个数量级
- 证明了该架构适用于LibriSpeech数据集,并能快速训练,该数据集包含了2484个发音人的将近820小时的语音数据。
- 证明了我们能够生成单调的注意力行为,避免了在语音合成中经常出现的错误情形。
- 对于单个说话人,我们比较了不同波形合成方法的质量,包括WORLD、Griffin-Lim和WaveNet
- 描述了Deep Voice 3 推理内核的具体实现,其能够在单一GPU机器上每天响应1000万次的查询请求。
模型架构
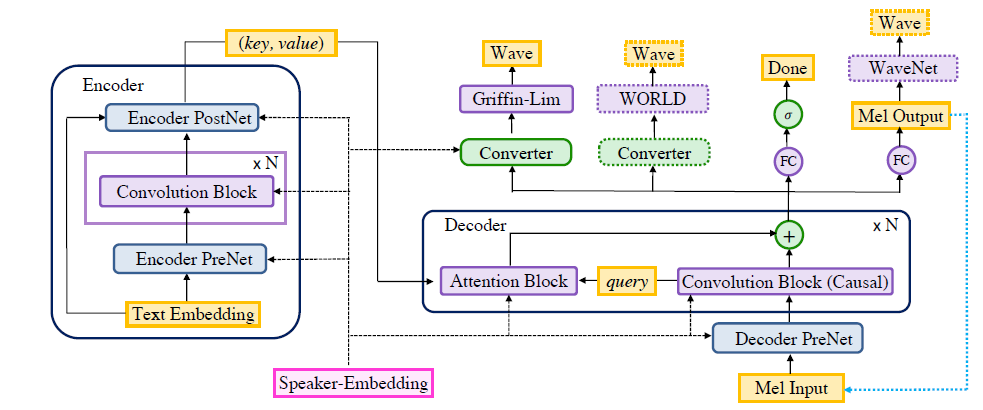
Deep Voice3 包括三个部分:
- Encoder:一个全卷积的编码器,将文本特征转换到中间的学习表示;
- Decoder: 一个全卷积的因果解码器,采用自回归的方式将从多级卷积注意机制学习到的表示解码到低维音频表示(美尔带频谱);
- Converter: 一个全卷积的后处理网络,能够从decoder的状态预测最终的输出特征(依赖具体的波形合成方法)。
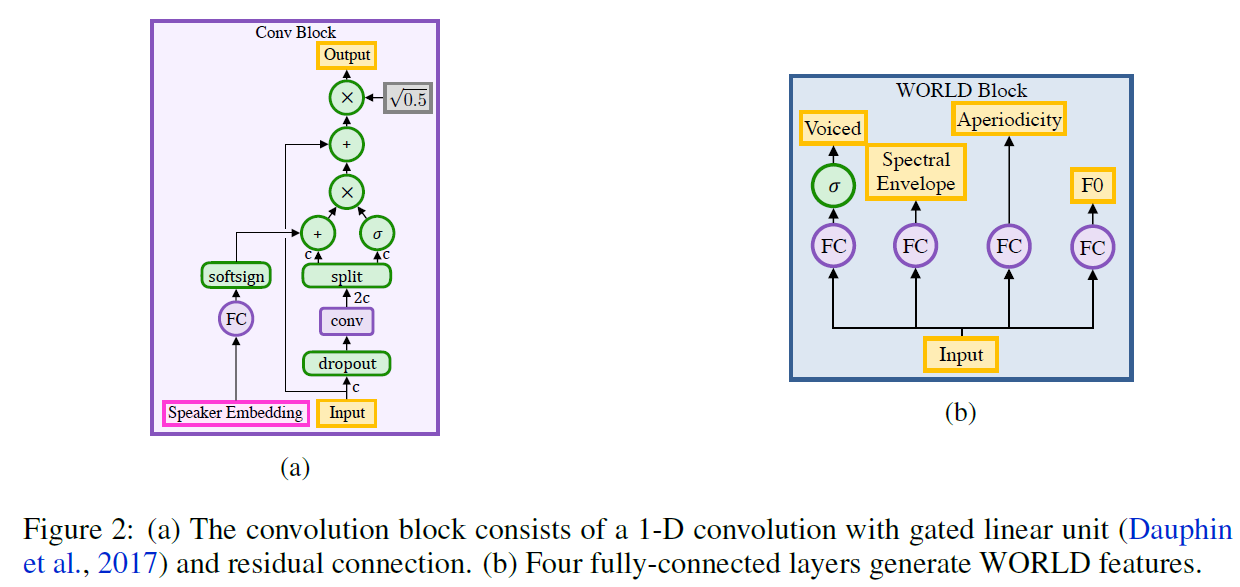
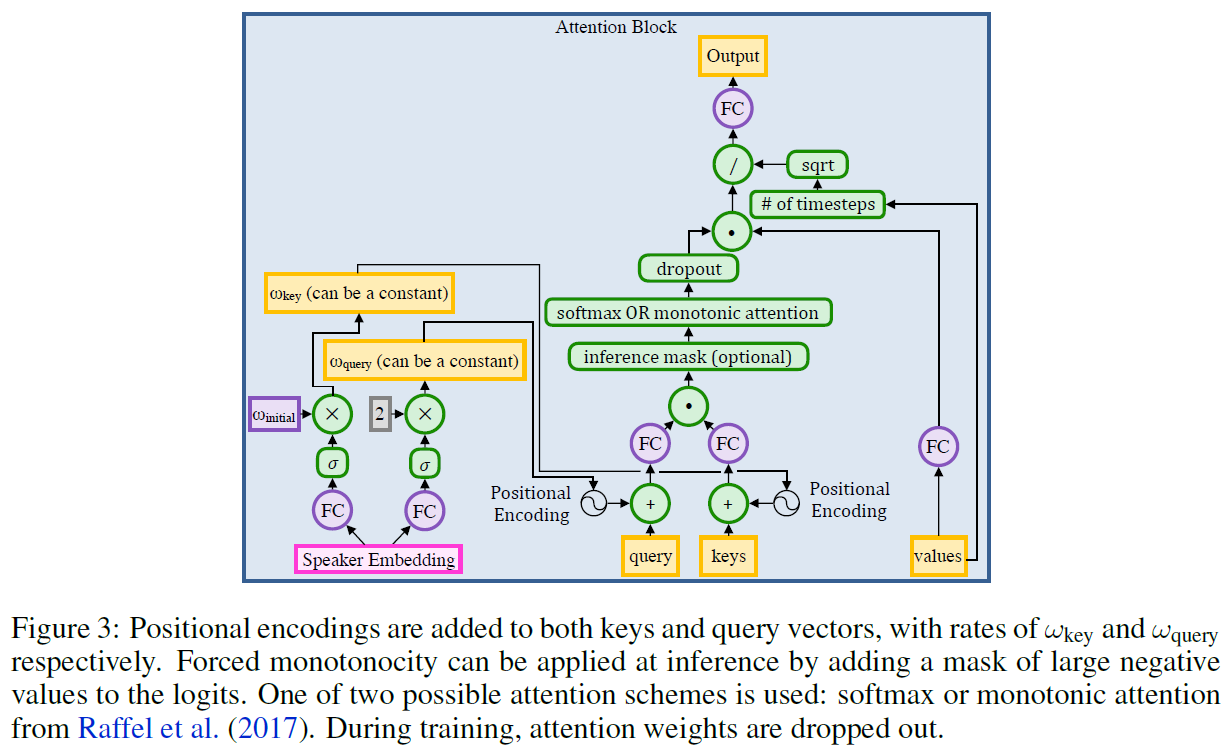
结果
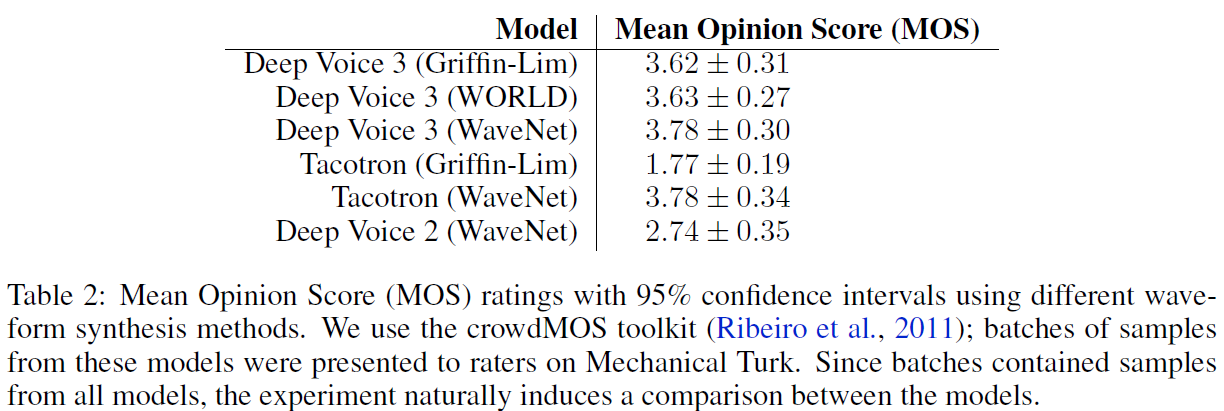

Deep Voice 3
http://zhaoshuaijiang.com/2017/10/26/paper-deep-voice-3/