浅谈语音合成方法
引言
从整个语音合成的发展历史来看,早期的机械式语音合成器反映了人们对语音产生机理了解得比较粗略,现代语音合成方法基本上都是采用一种语音模型来合成语音。近期的语音合成方法可以归纳为四种:1.物理机理语音合成;2.源-滤波器语音合成;3.基于波形拼接技术的语音合成;4.可训练的语音合成。5.基于神经网络的语音合成。
物理机理语音合成
物理机理语音合成方法是通过对人产生语音的物理结构进行建模,从而产生语音,比如,对发音过程中嘴唇、牙齿、下巴等运动进行建模。
近来,因为难以将它在现阶段推向实用,物理机理语音合成的研究受到制约。主要原因在于两个方面:一是对语音产生过程中发声器官的运动和变换进行度量非常困难;第二个原因是模型复杂、计算量非常大,相比于源-滤波器的语音合成模型,对声道气流特征和运动轨迹的数学建模非常复杂而且计算量非常大。
源-滤波器语音合成
源-滤波器语音合成基于这样一种声学理论,这种理论认为声音由激励和相应的滤波器形成。其中激励主要分为两种:一种是类似噪声的激励,主要形成非浊音语音信号;另一种是周期性的激励,主要生产浊音信号。
在该方式里,音库中预先存放各种语音合成单元的声道参数,这些参数根据控制规则的要求进行修正,以合成出各种语言环境下的语音。源-滤波器语音合成的结构框图,如下图所示。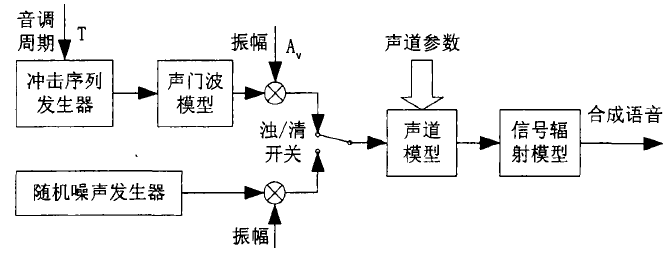
在基于源-滤波器的参数合成中,合成器的工作流程可以分为三步:
- 首先根据待合成音节的声调特性构造出相应的声门波激励源;
- 然后再根据协同发音、速度变换(时长参数)等音变信息在原始声道的基础上构造出新的声道参数模型;
- 最后将声门波激励源送入新的声道模型中,其输出就是符合给定韵律特性的合成语音。
LPC(线性预测分析)合成器和共振峰合成器是基于源-滤波器的参数合成器中最常用的两种方法。
LPC合成器
线性预测合成(LPC)以线性预测误差滤波器为基础来模拟声道。
共振峰合成器
把人的声道模型看成一个谐振波,语音信号的共振峰特性由这个腔体的谐振频率来表征,这种合成方法叫做共振峰合成。
基于波形拼接技术的语音合成
波形拼接合成方法的基本原理就是根据输入文本分析得到的信息,从预先录制和标注好的语音库中挑选合成的单元,进行少量的调整(也可以不调整),然后拼接得到最终的合成语音。其中用来进行单元挑选的信息可以是前端分析得到的韵律文本,也可以是生成的声学参数,或者二者兼有。由于最终合成语音中的单元都是直接从音库中复制过来的,其最大优势就是在于保持了原始发音人的音质。
可训练的语音合成
可训练的语音合成(Trainable TTS)的基本思想就是基于一套自动化的流程,根据输入的语音数据进行训练,并形成一个相应的合成系统。
在语音信号处理中,最普遍有效的建模方式就是隐马尔科夫模型(Hidden Markov Models, HMM),它在语音识别中已经有非常成熟的应用,目前的Trainable TTS也都是基于HMM进行参数建模。
基于神经网络的语音合成
2006年,Hinton等人提出深度学习的概念,深度学习在不同领域得到了很好的应用,并且也取得了不错的效果。2012年,Hinton等人就利用深度神经网络对语音识别进行声学建模。2013年,Zen等人实现了基于深度神经网络的参数式语音合成。
总结
随着计算机处理能力的不断提高,目前主要流行的是可训练的语音合成,并且为了提高合成语音的音质,一般会采用混合式语音合成方法,即基于HMM的单元挑选和波形拼接语音合成。将统计建模的思想引入到单元挑选和波形拼接中,结合了两种方法的优点,也取得了不错的效果。
参考文献
- 吴义坚. 基于隐马尔科夫模型的语音合成技术研究[D]. 中国科学技术大学, 2006.
- Ze H, Senior A, Schuster M. Statistical parametric speech synthesis using deep neural networks[C]//Acoustics, Speech and Signal Processing (ICASSP), 2013 IEEE International Conference on. IEEE, 2013: 7962-7966.
2014/5/21 21:12:59 Version 1
2014/5/29 22:37:52 Version 2