深度学习——在信号与信息处理中的应用
介绍
自从2006以来,深层结构学习,或者通常叫做深度学习(deep learning)、层次化学习(hierarchical learning),已经作为一个新的领域从机器学习中分离出来。
深度学习有很多不同的定义:
- 定义1:一类利用多层非线性信息处理的机器学习技术,用于监督的和非监督的特征抽取和转换,以及模式分析和分类。
- 定义2:机器学习的一个子领域,基于学习多层次表示的算法,用于对数据中复杂的关系建模。
- 定义3:机器学习的一个子领域,基于学习不同层次的表示,与一个层次化的特征或因子或概念相关;其中,高层的概念定义于低层的,相同的低层次的概念有助于定义高层次的概念。
- 定义4:深度学习是机器学习研究的新领域,使得机器学习更加接近它最初的目标:人工智能。
现在,深度学习流行的三个重要的原因:
- 快速提升的芯片处理能力(比如通用图像处理单元,GPGPU);
- 低成本的计算硬件;
- 机器学习和信号信息处理研究的最新进展。
深度学习成功应用的领域:
- 计算机视觉
- 音子识别
- 语音研究
- 传统的语音识别
- 语音和图像特征的编码
- 语义分类
- 手写体识别
- 信息检索
- 机器人
- 生物医药中的分子分析
深度学习的发展历程
到目前为止,大多的机器学习和信号处理技术都是利用浅层的结构。这些浅层结构最多包含1层或者2层的非线性特征转换。
这些浅层结构包括:
- 高斯混合模型(Gaussian Mixture Models, GMMs)
- 条件随机场(Conditional Random Fields, CRFs)
- 最大熵模型(Maximum Entropy Models, MaxEnt)
- 支持向量机(Support Vector Machines, SVMs)
- 逻辑回归(Logistic Regression)
- 核回归(Kernel Regression)
- 多层感知机(Multi-Layer Preceptrons, MLPs)
- 极限学习机(Extreme Learning Machine, ELMs)
人类的信息处理机制(比如视觉、听觉),都需要利用深层的体系结构来抽取复杂的结构,并且从丰富的感知输入中构建内在表示。
从历史角度来看,深度学习的概念最初是从人工神经网络的研究发展而来的。前馈神经网络、多层感知机含有多个隐层,都被认为是深层神经网络(DNNs),也是深层结构的典型代表。
深层模型中优化难题的解决,依靠三种技术:
- 更大数目的隐藏层节点数目;
- 更好的学习算法;
- 更好的参数初始化技术。
DNN中使用更多节点的隐藏层,可以显著地提升模型能力并且能够具有更多接近最优的参数配置。即便参数学习陷入局部最优,DNN的结果仍然表现得很好,因为陷入较差的局部最优的机会要比神经网络中使用少量神经元的时候小。但是,使用更深层、更宽的神经网络会在训练阶段要求更多的计算量,这也是为什么直到最近,研究人员才开始认真地探索研究更深、更宽的神经网络。
更好的学习算法有助于DNN的成功。比如,随机BP算法现在取代了批量模式的BP算法,用于DNN的训练。一部分原因是,当训练时在一台机器上进行、并且训练集很大的时候,随机梯度下降(SGD)算法是最有效的算法。但是,更为重要的是,随机梯度算法能够从局部最优跳出来,这得益于从单个样本或者一组样本中估计出来的噪声梯度(noisy gradients)。其他的算法,比如Hessian Free或者Krylov subspace 方法具有类似的能力。
对于DNN的非凸优化问题,显然更好的参数优化技术会得到更好的模型,因为优化是从初始化模型开始的。DNN参数初始化技术中最引人注目的是Hinton在2006年提出的无监督的预训练技术。这一类论文中,深层贝叶斯概率生成模型,叫做深度置信网络(DBN)被提出来。除了非监督预训练方法,监督预训练,有时候也称为区分式预训练也被证明是有效的。
深度学习的三类结构
深层结构的三种类型:
- 生成式深层结构:旨在捕获观测、可视数据的高阶关系,用于模式分析或者合成;或者刻画可视数据以及它们相关的类别的联合统计分布。在后一种情况下,贝叶斯规则的使用能够将该类型的结构转变成判别式。
- 判别式深层结构:旨在直接提供用于模式分类的判别能力。
- 混合式深层结构:目标是判别,并且在通过更好的优化或者正则化的生成式结构的帮助下。或者是,在上面的第一种类型的任何深层结构中,判别准则用来学习参数。
基本的深度学习术语:
- 深度置信网络(Deep Belief Network, DBN):包含多个隐藏层的统计生成模型。最高的两层之间是无向、对称的连接。较低的低层从高层接收从上到下的有向连接。
- 玻尔兹曼机(Boltzmann Machine, BM):一种对称连接的网络,像神经元那样,随机决定是开启还是关闭。
- 受限玻尔兹曼机(Restricted Boltzmann Machine, RBM):一种特殊的BM,包含一个可见层、一个隐藏层,可见层单元之间、隐藏层单元之间没有连接。
- 深度神经网络(Deep Neural Network, DNN):一种多层感知机,具有多个隐藏层,权重全连接,使用无监督或者有监督的预训练技术。
- 深层自编码(Deep auto-encoder)
- 分布表示(Distributed representation)
生成式深层结构
在生成式深层结构的不同子类中,基于能量的深层模型是最常见的。
另一种典型的生成式模型是深层玻尔兹曼机,简称为DBM。DBM包含多个隐层,并且相同层的变量之间没有连接。
另一个有代表性的深层生成式结构是sum-product network(SPN)。
循环神经网络(RNNs)也是另外一中重要的深层生成式结构,它的深度可以和输入数据序列的长度一样大。RNNs对于序列数据有很好的建模能力,但是直到最近才被广泛应用,一部分原因是他们由于“梯度爆炸”问题而十分地难以训练。
判别式深层结构
大多数信号和信息处理的判别式技术是浅层结构,比如隐马尔科夫模型、条件随机场。
就像之前讨论过的那样,RNNs已经被成功用作生成式模型。RNNs也可以用于判别式模型,其中输出是和输入数据序列相关的标记序列。
另一种判别式深层结构是卷积神经网络(CNN),其中的每个模块都包含一个卷积层和一个pooling层。CNN已经被发现是很有效的,并且已经被广泛应用在计算机视觉和图像识别中。
混合式深层结构
混合式主要是指深层结构同时包含或者利用了生成式和判别式的模型。在已经发表的关于混合式深层结构中,生成式部分大都被用来帮助判别,这也是混合式结构的最终目标。生成式建模是如何帮助、为什么会帮助判别,可以从两种角度来看:
- 从优化的角度来看,生成式模型可以为非线性问题提高很好的初始点,也是这个原因,深度学习中经常会使用预训练。
- 从正则化的角度看,生成式模型可以有效地控制模型的复杂度。
DBN,作为生成式深度结构,可以转换、用于具有相同网络结构的DNN的初始模型,DNN进一步进行判别式训练或者调优。
另外一个混合式深层结构的例子是,DNN的权重也是从生成式的DBN初始化而来,但是使用序列级别的判别准则,而不是常用的帧级别的准则。
更进一步的混合式深层结构的例子是利用生成式模型对深层卷积神经网络(deep CNNs)做预训练。就像全连接的DNN,预训练相比于随机初始化,会帮助提高深层CNN的性能。
混合式深度结构的最后一个例子是语音翻译,其中,一个任务是判别式的(语音识别),得到的输出(文本)作为输入服务于第二个判别任务(机器翻译)。整个系统实现了语音翻译:从一种语言的语音翻译到另外一种语言的文本,这是一个包含生成式和判别式的两个阶段的深层结构。语音识别和机器翻译的模型都是生成式的,但是,他们学习到的参数都是用来做判别。
生成式:深层自编码
深层自编码是DNN的一种特例,他的输出和输入有相同的维度,在隐藏层可以有效地编码和表示原始的数据。值得注意的是,自编码是非线性的特征提取方法,并且不需要使用类别标记。特征提取旨在保存信息而不是完成分类任务,尽管有时候这两种目标是相关的。
深层自编码抽取语音特征
堆栈去噪自编码
在大多数的应用中,自编码中的编码层的维度要比输入层的小。但是,在一些应用中,我们期望编码层比输入层宽,在这种情况下就是要防止神经网络学习微小特征的映射函数。
举例来说,在堆栈去噪自编码中,在输入数据中加入了随机噪声。这样做有几个目的:第一,通过强制将输出与原始不失真的输入数据匹配,能够避免模型学习到微小特征的答案;第二,由于加入了随机噪声,模型的学习会对测试数据中相同的失真鲁棒;第三,由于每个失真的输入样本是不同的,这就很大程度上增加了训练集,这样能够消除过拟合问题。
转换自编码
混合式:预训练深层神经网络
判别式:深层堆网络及其变体
虽然DNN已经证明在识别和分类任务上,包括语音识别和图像分类,有非常强的能力,但是训练一个DNN模型在计算量上是非常大的。特别地,传统训练DNN的技术,在调优阶段利用随机梯度下降算法,这在机器上进行并行计算是非常困难的。这里,我们提出了一个新的深度学习结构,深层堆栈网络(Deep Stacking Network,DSN),用来解决学习可扩展性问题。
DSN设计的核心思想和堆栈的概念相关,最初在(Wolpert,1992)提出,就是说函数或者分类器的简单模块首先组合,然后相互之间的顶端堆栈起来,用来学习复杂的函数和分类器。
在语音识别中的应用
传统的神经网络已经在语音识别中使用了很多年了。单独使用神经网络的时候,它的性能远不如性能先进的利用GMM对观测概率近似的HMM系统。
有实验已证明三音子的DNN-HMM的性能显著优于最先进的HMM系统。三个因素帮助DNN成功:使用三音子作为DNN的建模单元,使用可靠的三音子GMM-HMM生成每个状态的边界,调整跳转概率。
除了RBM、DNN和DSN,其他一些深层模型也被用来做语音处理和相关的应用。比如,深层CRF,堆叠了很多层CRF,已经成功应用于语言的辨别、音子识别、自然语言处理中的序列标注、语音识别中的置信校准等任务。更进一步,RNN早就成功应用到了音子识别,因为训练的复杂度,它不容易被复现到语音识别任务中。之后,RNN的学习算法得到了显著的提升,最近利用RNN也取得了更好的结果。RNN也被用到了音乐处理中,其中利用“rectified linear”隐藏层单元,取代了“logistic”和“tanh”非线性单元。Rectified linear units计算函数y=max(x,0),这就可以产生稀疏的梯度,减少了RNN中不利因素的扩散,并且可以更快地训练。
在语言模型中的应用
语言模型使用浅层神经网络已经有很长的历史了,语言模型是语音识别、机器翻译、文本信息检索、以及自然语言处理的重要组成成分。语言模型是一个捕获自然语言中词序列分布的显著统计特性的函数。一个基于神经网络语言模型利用神经网络的能力来学习分布表示,从而减少维度灾难带来的影响。
统计语言模型的优点:对没有出现在训练序列中的序列有较好的泛化能力。因为神经网络趋向于将相近的输入映射到相近的输出,对具有相似特征的词序列的预测会映射到相似的预测。
利用RNN构建大尺度的语言模型,在训练RNN的过程中获取了不断增加的梯度,实现了训练过程的稳定和快速收敛。
在自然语言处理中的应用
在自然语言处理的出名的或者有争议的工作中,Collobert和Weston (2008)实现一个卷积DBN作为通用模型,来解决一系列经典问题,包括词性标注、分词、命名实体识别、语义角色标注、相似词判断。
前人的工作中一个重要的方面是,通过神经网络的子层,实现从具有很高维度的稀疏向量的原始的词表示到一个低维的、实数向量表示的转换。这就是“word embedding”:目前广泛应用到自然语言处理和语言建模中。
最近一项有趣的利用深度学习实现自然语言处理的工作出现在(Socher et al., 2011),一个递归神经网络(recursive neural network)用来构建深层结构。这种深度学习方法提供了在自然语言分析上的极好的表现。
在信息检索中的应用
这里我们讨论DBN在文档索引和信息检索中很有趣的应用(Salakhutdinov and Hinton, 2007; Hinton and Salakhutdinov, 2010)。DBN的最后一层不仅容易推断,并且相比于信息检索中已经广泛使用的潜在语义分析和传统的TF-IDF方法,能够给出每个文档一个基于词频特征的更好的表示。一个深层的生成模型DBN用于上述目的。简而言之,DBN中最低的层表示词频的向量,高的层次表示文档的紧凑的二值编码。
模型训练好之后,检索的过程开始于将每个查询文档映射到一个128bit的二值编码,通过模型的前馈、根据门限而得到。之后,计算查询二值编码和所有其他文档的128比特二值编码的汉明距离。
上述信息检索中对于文本文档编码的想法,已经在音频文档和语音特征编码问题上开始探索。
在图像、视觉、多任务处理的经典应用
原始的DBN和深层自编码被成功应用到图像识别和降维(编码)任务上(MNIST)。两种策略用来提高DBN的鲁棒性:第一,DBN的第一次以稀疏方式连接,作为正则化模型的一种方式;第二,概率去噪算法的发展。DBN也被成功应用到对图像创建紧致并且有意义的表示,用来进行检索。
具有卷积结构的深层结构,已经被发现能够有效、并且广泛应用在计算机视觉和图像识别中。
具有多任务学习能力的DNN应用到多语种语音识别。这些结构背后的想法是:DNN中的隐藏层,进行适当地学习后,在不同语言的声学数据中共享隐藏层因子的条件下,可以作为复杂特征的转换。多任务学习方法能够完全不需要无监督预训练步骤,能够用更少的轮数来训练DNN。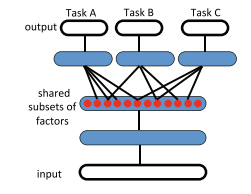
结语
深度学习是一种新兴的技术。尽管已经有令人兴奋的结果报告出来,但是还有很多需要去做。重要的是,还没有深度学习的研究人员的经验表明,单一的深度学习算法能够成功应用到所有的分类任务中。
最近几年,机器学习越来越依赖于大规模数据集。深度学习算法表现的好坏将依赖于数据的数量和计算能力。
DNN的使用以及相关的深度模型的一个主要障碍是:它们需要相当的知识和技巧去选择超参数,比如学习率、正则化的力度、隐藏层数目、每层的节点数等等。
最后,需要在很多方面建立深度学习的坚实的理论基础。比如说,深度学习在无监督学习中的成功应用还没有像有监督学习那样得到证明。
参考文献
- Li Deng and Dong Yu. Deep Learning for Signal and Information Processing. 2013