Paper Reading:《STATISTICAL PARAMETRIC SPEECH SYNTHESIS USING DEEP NEURAL NETWORKS》
论文信息
- 作者:Heiga Zen, Andrew Senior, Mike Schuster
- 单位:Google
- 会议:ICASSP
- 发表日期: 2013
- 论文链接:http://ieeexplore.ieee.org/xpls/abs_all.jsp?arnumber=6639215
简介
利用深层神经网络(Deep Neural Network,DNN)取代基于隐马尔科夫模型(Hidden Markov Models,HMMs)的语音合成中的决策树聚类和高斯混合模型(Guassian Mixture Models, GMMs),以提高声学建模的准确性。
参数式语音合成中影响语音合成质量的三个因素:
- 声码器自身的局限
- 声学模型的准确性
- 过平滑问题
该文章关注声学模型的准确性。
决策树与DNN特性的比较
- 决策树不能有效表达文本特征中的复杂函数;DNN可以表示。
- 决策树依赖输入空间的分区,并且分别使用一组参数来对应一个分区;DNN有更好的泛化能力,它的权重是从所有的训练数据中训练得到的。
- 在训练阶段,利用反向传播算法训练DNN的计算量要远远大于构建决策树;在预测阶段,DNN需要在每一层做矩阵的乘法,决策树只需要从根节点遍历到叶子节点。
- 决策树可以提高可以解释的规则,而DNN中的权重则很难解释。
基于DNN的语音合成
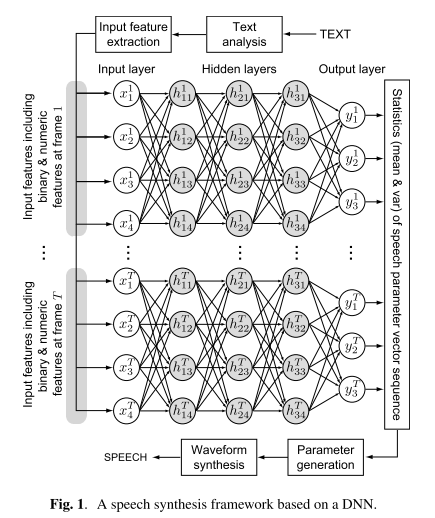
实验
实验设置
- 数据:专业女性,英语语音数据,33000句
- 输入特征:342维二值特征,用于类别上下文信息(例如音子ID、重音标记);25维的数值特征,用于数值上下文信息(例如词中的音节数目、当前音节在短语中的位置)
- 输出特征:40维梅尔倒谱、对数基频、5带宽的非周期分量,以及他们的一阶、二阶差分,共3*(40+1+5)=138维
- DNN:权重随机初始化、基于小批量随机梯度下降(minibatch stochastic gradient descent,SGD)的反向传播算法、sigmoid作为激活函数
客观评价
客观指标包括: - Mel-cepstral distortion:谱参数的距离
- Voiced/Unvoiced Error Rate:清浊音判断错误率
- RMSE in log F0:基频在对数域上的均方误差
- Aperiodicity distortion:非周期分量的距离
下图分别展示出了在不同模型条件下的客观指标。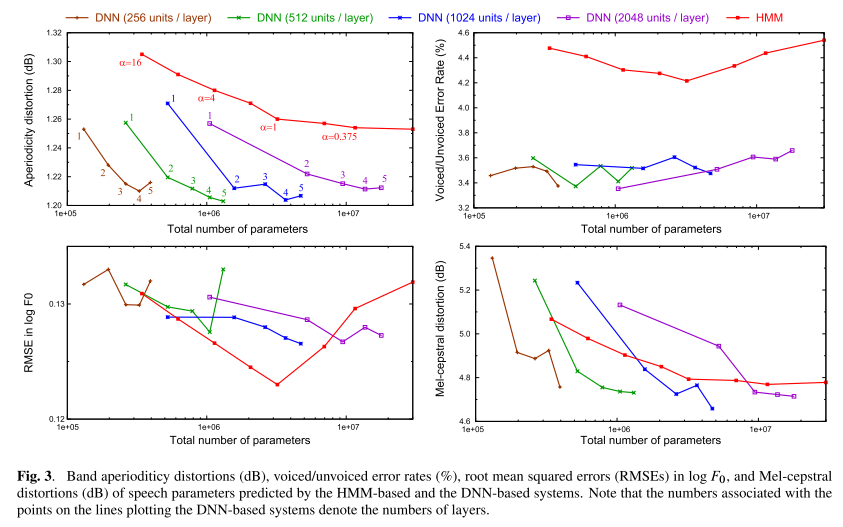
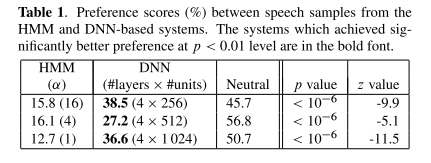
主观评价
结论
这篇文章利用DNN实现了语音合成。基于DNN的语音合成具有解决基于HMM的方法中决策树聚类的局限的潜力。
客观评价证明利用深层的结构提高了基于神经网络的系统的性能。另外,在相似的模型参数条件下,在主观的测听中,基于DNN的系统要比基于HMM的系统有更好的性能。
基于HMM的系统相比于基于DNN的系统的其中一个优点就是小的计算量。在合成阶段,基于HMM的系统遍历决策树来查找每个状态的统计量;另一方面,基于DNN的系统从输入到输出的映射包括在每一帧都有大量算术运算。
下一步的工作包括:减少基于DNN的系统的计算量;增加更多的输入特征,包括重音等这些弱特征;以及探索一个更好的对基频的建模方法。
Paper Reading:《STATISTICAL PARAMETRIC SPEECH SYNTHESIS USING DEEP NEURAL NETWORKS》
http://zhaoshuaijiang.com/2014/12/10/paper_dnn_speech_synthesis/