Paper Reading: 《DEEP MIXTURE DENSITY NETWORKS FOR ACOUSTIC MODELING IN STATISTICAL PARAMETRIC SPEECH SYNTHESIS》
论文信息
- 作者:Heiga Zen, Andrew Senior
- 单位:Google
- 会议:ICASSP
- 发表日期: 2014
- 论文链接:https://wiki.inf.ed.ac.uk/twiki/pub/CSTR/Speak13To14/p3872-zen.pdf
简介
利用深层神经网络(DNNs)的参数语音合成(SPSS),被证明具有生成自然的合成语音的能力。然而,语音合成中基于DNN的声学建模还有不足之处,例如目标函数是单峰的、缺少预测方差的能力。
为了解决这些局限,本文研究了利用混合密度的输出层,它能够在给定输入特征条件下,估计输出特征的全概率密度函数。实验的客观和主观结果表明利用混合密度输出层提高了预测的声学特征的准确性、以及合成语音的自然度。
然而,语音合成中基于DNN的声学建模有一些局限,本文解决了DNN的以下两个局限:
- 基于DNN的声学模型,利用均方误差(Mean Squared Error,MSE)作为它的目标函数,不具有对比单高斯分布更复杂分布的建模能力。
- 一个人工神经网络(ANN)输出只提供了均值。统计参数语音合成中所使用的参数生成算法,需要声学特征的均值和方差,在静态和动态特征的约束下,来得到声学特征最大可能的轨迹。
为了解决这些局限,本文研究了利用混合密度函数作为SPSS的声学模型。MSD能够在输入特征的条件下,给出输出特征的概率密度函数。MSD可以是多峰的回归,并且可以预测方差。
基于MDN的语音合成
MDN联合了一个混合模型和一个人工神经网络。本文利用了一个基于高斯混合模型的MDN。一个MDN M 将输入特征x映射到GMM的参数,这样就就给出了在输入特征条件下,输出特征y的全概率密度函数。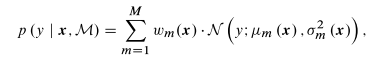
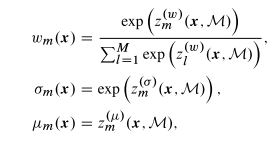
其中,$z_m^(w)$,$z_m^(\sigma)$,$z_m^(\mu)$是MDN输出层参数,分别是GMM中第m个分量的混合权重、方差、均值。
训练MDN的过程就是在给定数据条件下,最大化M的对数似然: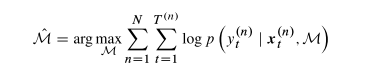
下图是基于深层MDN的语音合成的框图。首先,将输入文本转换成文本特征序列;第二,每个语音单元的时长通过一个时长预测模块得到;然后,在给定文本特征的条件下,利用训练好的DMDN,预测包括谱参数和激励参数以及它们的差分在内的声学特征的GMM;利用预测的GMM序列,使用语音参数生成算法,可以得到平滑的声学特征轨迹;最后,波形生成模块,对给定的声学特征输出合成的语音波形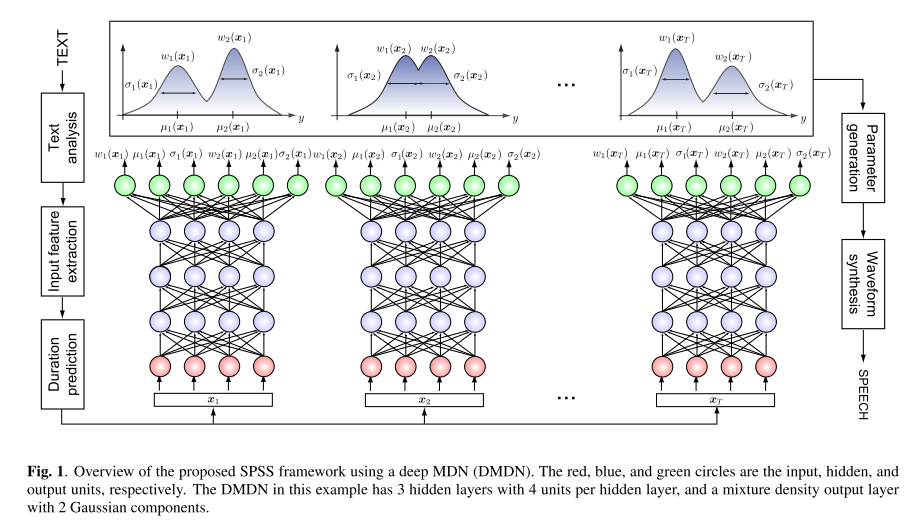
实验
实验设置
- 数据:专业女性,英语语音数据,33000句
- 输入特征:342维二值特征,用于类别上下文信息(例如音子ID、重音标记);25维的数值特征,用于数值上下文信息(例如词中的音节数目、当前音节在短语中的位置)
- 输出特征:40维梅尔倒谱、对数基频、5带宽的非周期分量,以及他们的一阶、二阶差分,共3*(40+1+5)=138维
- MDN:基于DNN系统的权重,通过最小化输出特征和预测值之间的均方误差来训练得到;基于MDN系统的权重,通过最大化给定训练数据条件下的模型对数似然来得到。
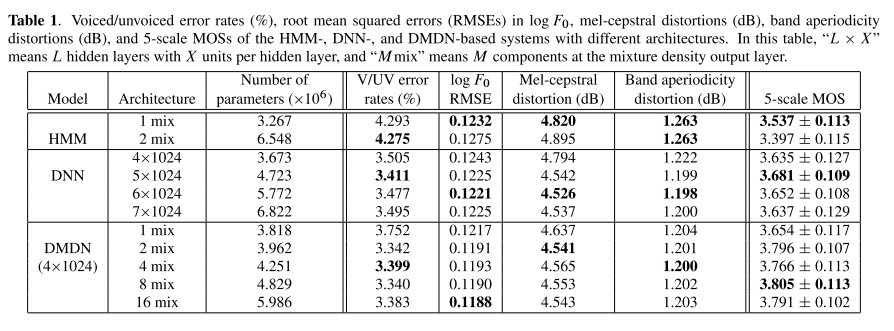
客观评价
主观评价
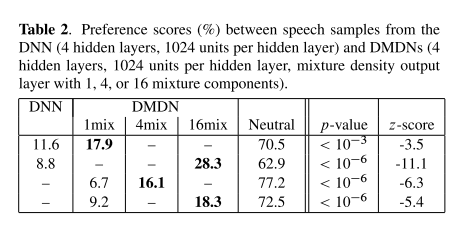
从表格中可以看到,具有方差对预测倒谱以及非周期分量有帮助,并且可以提高合成语音的自然度。GMM的多个分量,有助于基频的预测、以及提高合成语音的自然度。
结论
本文通过混合密度模型(MDNs)扩展了基于DNN的SPSS。基于DMDN的方法可以缓解语音合成中基于DNN的声学建模的局限:缺少方差,目标函数的单峰特性。客观和主观评价表明,具有方差和多个混合分量的混合密度输出层有助于提高预测声学特征的准确性,并且显著提高合成语音的自然度。
下一步工作包括探索更好的网络结构以及训练网络的优化算法。利用参数生成算法的DMDN的评价,也需要考虑到global variance。