Paper Reading:《TTS Synthesis with Bidirectional LSTM based Recurrent Neural Networks》
论文信息
- 作者:Yuchen Fan, Yao Qian, Fenglong Xie, Frank K. Soong
- 单位:上海交通大学,MSRA
- 会议:INTERSPEECH
- 发表日期: 2014
- 论文链接:https://mazsola.iit.uni-miskolc.hu/~czap/letoltes/IS14/IS2014/PDF/AUTHOR/IS140552.PDF
简介
采用双向LSTM单元的RNN能够捕捉参数式语音合成中一个语音句子中的任意两时刻的相关性。
DBLSTM RNN
LSTM(Long Short Term Memory)的结构如下图所示。LSTM能够解决传统RNN中的梯度消失问题。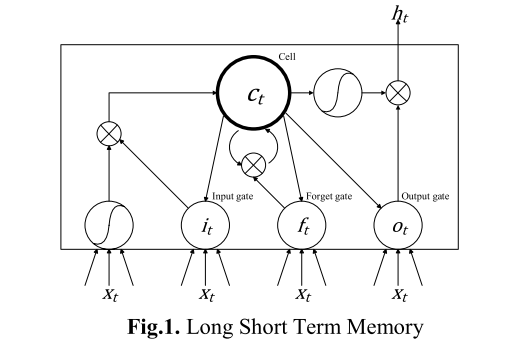
下图是双向RNN的结构,其能够访问前向和后向的上下文。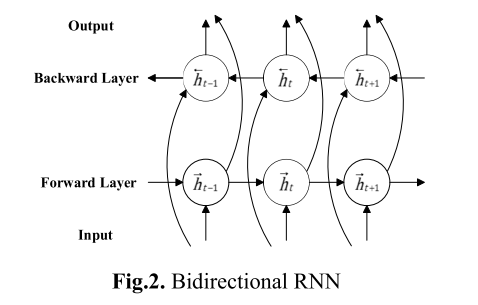
深层双向LSTM是深层双向RNN和LSTM的结合。
基于RNN的语音合成
下图是基于DBLSTM-RNN的语音合成系统框图。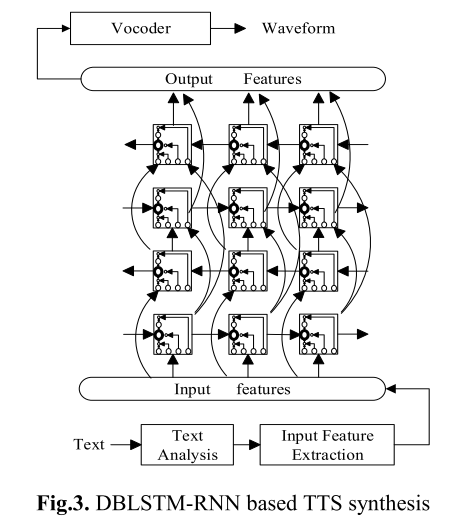
基于DBLSTM-RNN的语音合成系统中,丰富的上下文作为输入特征,包括二值特征(例如音子标记、词性标记等)和数值特征(例如短语中词的数目、当前帧在当前音子的位置);输出特征就是声学特征,例如谱包络、基频。输入特征和输出特征是通过训练好的HMM做时间上帧级别的对齐。
在RNN的训练过程中,训练的准则是最小化输出特征和目标之间的均方根误差。BPTT(Back-propagation through time)是常用的算法。
在合成阶段,输入文本首先通过文本分析转换成输入特征向量,然后输入特征向量通过训练好的DBLSTM-RNN映射到输出特征向量。
实验
实验设置
- 数据:专业女性,美式英语语音数据,5000句(大约5小时)
- 输入特征:355维特征,其中319维是二值特征,其余是数值特征。
- 输出特征:清浊音标记、基频、LSP、增益,及其动态特征,共127维。
- 模型配置:
- HMM:MDL=1用于LSP和F0决策树生成
- DNN:6个隐藏层,每个隐藏层512个节点
- DNN_B:3个隐藏层,每个隐藏层1024个节点
- Hybrid_A:DNN和BLSTM-RNN的混合,4个隐藏层,每个隐藏层512个节点,其中底部的3个隐藏层是利用sigmoid作为激活函数的前馈网络,上部的隐藏层是具有LSTM的双向RNN(256个前向节点和256个反向节点)
- Hybrid_B:混合结构和Hybrid_A类似,但是底部的2层隐藏层是前馈结构,上部的2层隐藏层是BLSTM-RNN(256个前向节点和256个反向节点)
实验结果
客观评价
下表是客观评价的结果。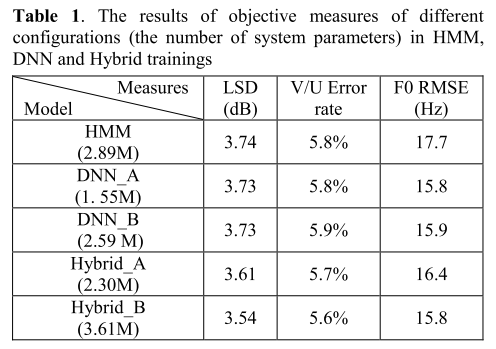
主观评价

结论
实验结果表明,BLSTM-RNN和DNN的混合系统要优于基于HMM的系统和基于DNN的系统,主要原因是该混合系统能够捕捉到一个句子中的深层信息。
Paper Reading:《TTS Synthesis with Bidirectional LSTM based Recurrent Neural Networks》
http://zhaoshuaijiang.com/2014/12/15/paper_rnn_tts/