感知机
简介
1957年Rosenblatt提出感知机(perceptron),成为神经网络和支持向量机的基础。感知机是二类分类的线性分类模型,输入是实例的特征向量,输出是实例的类别。感知机学习的目标是求出将训练数据进行线性划分的分离超平面,感知机属于判别模型。
感知机模型
输入空间是$X \subseteq R^n$,输出空间是$y={+1,-1}$。由输入空间到输出空间的函数$f(x)=sign(w \cdot x+b)$,称为感知机。其中,$w$和$b$是感知机模型参数,$w\in R^n $叫做权重或者权重向量,$b\in R$叫做偏置。sign是符号函数,即$sign(x)= +1, x\ge 0$;$sign(x)= -1, x<0$
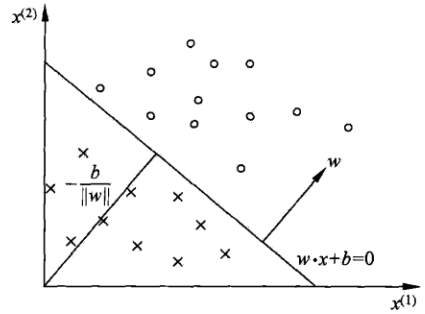
感知机学习策略
感知机学习的策略是在假设空间中选取使损失函数最小的模型参数。
假设训练数据集是线性可分的,感知机学习的目标是求得一个能够将训练集正实例点和负实例点完全正确分开的分离超平面。
为了找出这样的超平面,确定感知机模型参数,需要确定一个学习策略,也就是定义经验损失函数并将损失函数极小化。自然地,损失函数的一个选择是误分类点的总数。但是,这样的损失函数不是参数$w,b$的连续可导函数,不易优化。损失函数的另一个选择是误分类点到超平面的总距离,这也是感知机所采用的。
感知机学习的损失函数定义为$L(w,b)=-\sum_{x_i \in M} y_i (w \cdot x_i +b)$
其中,$M$是误分类点的集合。这个损失函数就是感知机学习的经验风险函数。
感知机学习算法
感知机学习算法是误分类驱动的,具体是采用随机梯度下降法。
感知机学习算法的原始形式
给定一个训练数据集,求参数$w,b$,使其成为损失函数极小化的解: $min L(w,b)=-\sum_{x_i \in M} y_i (w \cdot x_i +b)$,其中$M$为误分类点的集合。
感知机学习算法是误分类驱动的,具体是采用随机梯度下降法。首先,任意选取一个超平面$w_0,b_0$,然后用梯度下降法不断极小化目标函数。极小化过程中不是一次使$M$中所有的误分类点的梯度下降,而是一次随机选取一个误分类点使其梯度下降。
假设误分类点集合$M$是固定的,那么损失函数$L(w,b)$的梯度为:
- $\nabla _w L(w,b) = -\sum_x y_i x_i$
- $\nabla_b L(w,b) = -\sum_x y_i$
随机选取一个误分类点$(x_i,y_i)$,对$w,b$进行更新:
- $w \leftarrow w + \eta y_i x_i$
- $b\leftarrow \eta y_i$
其中,$\eta(0<\eta \ge 1)$是步长,又称为学习率。这样,通过迭代以期损失函数$L(w,b)$不断减小,直到0为止。
感知机学习算法
输入:训练数据集
输出:$w,b$;感知机模型$f(x)=sign(w \cdot x+b)$
- 选取初值
- 在训练集中选取数据
- 如果 $y_i(w \cdot x_i + b) \le 0$: $w \leftarrow w + \eta y_i x_i$;$b\leftarrow \eta y_i$
- 转至2,直至训练集中没有误分类点。
该学习算法的直观解释是:当一个实例点被误分类,即位于分离超平面的错误一侧时,则调整$w,b$的值,使分离超平面向该误分类点的一侧移动,以减少误分类点与超平面间的距离,直至超平面越过该误分类点使其被正确分类。
算法的收敛性
- 好的
- 电话
误分类的次数是有上界的,经过有限次搜索可以找到将训练数据完全正确分开的分离超平面。也就是说,当训练数据集线性可分时,感知机学习算法原始形式迭代时收敛的。