Tacotron--一种完全端到端的语音合成模型
论文信息
- 发表机构:Google
- 发表时间:2017-04
- 论文链接:https://arxiv.org/pdf/1703.10135.pdf
简介
现代的语音合成(Text-to-Speech,TTS)是很复杂的系统流程。对于参数语音合成,包括从语言抽取特征的文本处理、时长模型、声学模型预测声学特征、基于复杂信号处理的声码器。这些模块都是基于专家知识、需要精心设计。另外这些模块都是独立训练的,每个模块的错误会累积成更多的错误。TTS系统的复杂性导致当建立新系统时需要大量的工程量。
TTS是一种转换问题:将高度压缩的文本“解压”成音频。
本文提出了Tacotron,一种引入注意力(attention)机制的基于序列到序列(sequence-to-sequence,seq2seq)的端到端生成式TTS模型。我们的模型将文本字符作为输入、原始语谱图作为输出,并应用一些技术提高seq2seq模型的能力。
Tacotron可以完全地随机初始化、从头开始训练、它不需要音子级别的对齐,所以可以很轻松地利用大量带文本标注的声学数据。
相关工作
WaveNet
DeepVoice
Char2Wav
模型架构
model architecture
Tacotron的主要结构是含有attention机制的seq2seq模型。下图展示了模型结构,包括一个编码器(encoder)、一个基于attention的解码器(decoder)、一个后处理网络。在高一级层次上,模型以字符作为输入,预测帧级别语谱,然后可以进一步转成波形。如下图Figure 1所示。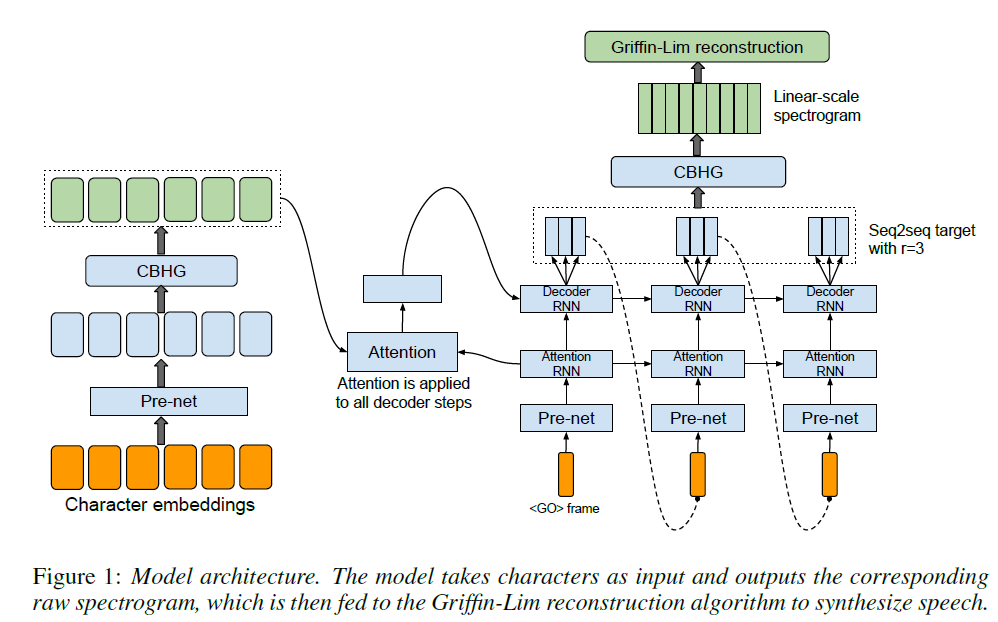
CBHG
CBHG包括一个1-D的卷积滤波,接着是高通网络以及一个双向GRU。如下Figure 2所示。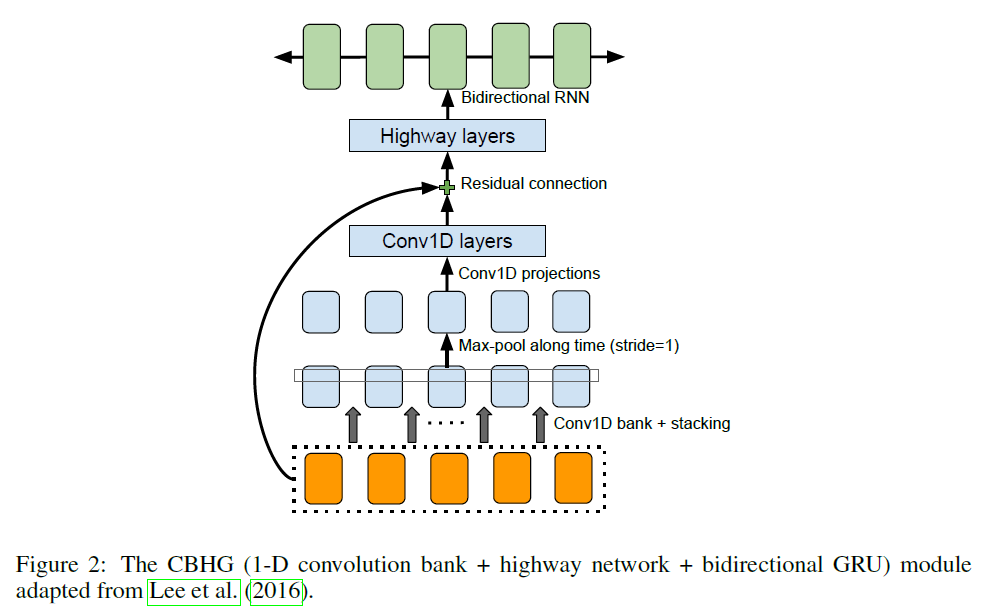
Encoder
Encoder的目标是提取鲁棒的文本特征序列。encoder的输入是字符序列,每个字符用one-hot向量或者嵌入式连续向量表示。对于每个嵌入式输入,我们应用了非线性变换,称为“pre-net”。在实际应用中,采用dropout瓶颈网络作为pre-net,有助于网络收敛和泛化能力。CBHG模块利用attention模块将per-net的输出转换成最终的encoder表示。我们发现基于CBHG的encoder不仅可以降低过拟合,相对于多层的RNN encoder可以减少发音错误。
Decoder
我们使用简单的全连接输出层来预测decoder的目标。一个重要的技巧是在每个解码步骤预测多个不重叠的输出帧。一次预测r帧,使得整体的decoder数量降低为原来的r分之一,从而减小了模型大小、训练时间和推理时间。更重要的是,这项技巧可以加速收敛速度,并且可以更快地从attention中学到更稳定的对齐。
后处理与波形合成
后处理网络的任务是将seq2seq的输出转换成可以合成波形的输出。
采用Griffin-Lim算法根据预测的语谱合成波形。
模型细节
实验
MOS测试
我们进行了MOS测试,要求被试者根据满分为5分的李克特量表对自然度打分。测试以众包的形式给母语人士测听。
测试结果如Table2所示。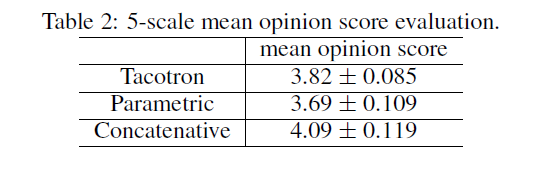
#总结
文章提出了Tacotron,一种端到端的生成式TTS模型,其将字符序列作为输入,语谱作为输出。使用一个简单的波形合成模块,在英文上可以达到3.82的MOS(mean option score,满分为5分)得分,自然度超出了产品级参数合成系统。