语音识别概述
引言
语音识别定义
语音识别,亦称自动语音识别(Automatic Speech Recognition,ASR)或语音文本转换(Speech to Text, STT),
是一种将语音转为文本的技术。当前的语音识别一般均特指大词汇量连续语音识别。
语音识别应用
语音识别有着广泛的应用,按照使用场景的不同,可以分为以下几类:
- 语音输入:语音输入法、语音搜索等。
- 语音助手:手机、音箱、穿戴设备上的语音助手,例如Siri、Cortana、Alexa等。
- 智能座舱:车载控制、娱乐等车载语音交互,例如NOMI。
- 智能家居:家居控制、娱乐等家居语音交互,例如小爱同学等。
- 电话客服:智能外呼、IVR、客服质检等。
- 商务办公:线上线下会议直播的字幕上屏展示。
- 语音审核:这类应用面向在线直播、电台等,检测是否存在违规违法内容。
语音识别类别
根据应用场景对实时性的要求高低,可以分为:
- 实时语音识别:要求系统低延迟,在两百毫秒以内;一般以语音流的方式实时地识别。典型的例子包括语音助手等语音交互、字幕实时上屏。
- 非实时语音识别:不要求实时返回结果;一般是一句话识别或文件语音识别。会议纪要转写等录音的语音识别属于这类。
根据系统实现架构,可以分为
- 经典语音识别:系统由声学模型、语言模型、发音词典、解码器几个部分组成。系统模块较多,搭建较为复杂;各个模块‘分工明确’ 模型结构相对简单,不依赖大量训练数据,在小数据集上有一定优势。
- 端到端语音识别:系统由一个模型实现从语音到文本的直接转换。深度学习引入语音识别之后,端到端的方式逐步成为研究热点。单个模型没有级联累积错误,而且系统搭建相对简单;但由于模型规模较大,需要更多的数据和训练成本。
评价指标
语音识别精度的评测是基于带标注的测试集,其数据规模从几千到上万句不等。
中文一般采用字错误率(character error rate, CER),英文一般采用词错误率(word error rate, WER)。CER和WER本质其实是一样的,只是计算的粒度不同。二者的核心都是对比参考答案和识别结果两个序列。
下面介绍WER的计算方法,将计算粒度从词换成字就是CER。
计算方法
如果两个序列长度相同,依次对比相应顺序的词是否相同,统计出错误个数,即可计算出错误率。但是实际情况两个序列长度不一定相同,有可能识别结果会多字或者少字,此时就无法直接按照顺序去对比。
WER的计算和生物信息学中的序列比对十分类似,可以参考序列比对的计算,引入动态规划算法。

- S is the number of substitutions,
- D is the number of deletions
- I is the number of insertions
- N is the number of words in the reference, N=S+D+C
相关工具:
学术研究
学术会议:
- ICASSP
- INTERSPEECH
- ASRU:IEEE Automatic Speech Recognition and Understanding Workshop
- ISCSLP
比赛:
开源数据集
中文:
- AISHELL-1: An open-source 178 Hours Chinese Mandarin speech corpus
- WenetSpeech: A 10000+ Hours Multi-domain Mandarin Corpus for Speech Recognition
英文:
- LibriSpeech: A Large-scale (1000 hours) corpus of read English speech
- GigaSpeech: An Evolving, Multi-domain ASR Corpus with 10,000 Hours of Transcribed Audio
多语种:
- Emilia: 以中英文为主的开源语音数据集,主要包括以下几种语言:
Language Duration (hours) En 46,828 Zh 49,922 De 1,590 Fr 1,381 Ja 1,715 Ko 217
开源框架
- Whisper: OpenAI 开源的Whisper语音识别模型,支持多语种语音识别、语音翻译。更多内容参考知乎
- Athena:端到端的语音处理工具,提供了语音识别、语音合成、语音活动检测、声纹识别等能力。
- ESPNet: 端到端的语音处理工具,提供了语音识别、语音合成、语音翻译、机器翻译、语义理解、语音增强、语音分离等能力。
- WeNet: 借鉴了ESPNet中语音识别的实现,并提供了工业界落地的实现。
- Kaldi: 经典语音识别的开源框架,非端到端的模型框架。
- k2+icefall+lhotse: 新一代语音识别框架,涵盖了主流的模型结构,具备先进的模块化设计:模型底层实现(k2)、数据模块(lhotse)、ASR样例(icefall)、部署(sherpa)。
语音信号与特征
语音的产生过程
声带利用振动,将肺部送来的气流转换成声波,从而产生声音。
数字信号
特征
语音识别的声学特征一般为梅尔倒谱系数(Mel-scale Frequency Cepstral Coefficients,MFCC)或者 Filter Bank(FBank)。
MFCC的计算流程如下:
- 预加重
- 分帧
- 加窗
- 快速傅里叶变换(FFT)
- Mel滤波器组
- 对数运算
- 离散余弦变换(DCT)
FBank的计算流程和MFCC很相似,只是没有做第七步的离散余弦变换。
因为没有DCT,FBank特征各维度间具有较高的相关性,可以被DNN等深度神经网络很好地利用,因此FBank较MFCC具有更好地精度。
然而,对于GMM等模型忽略了不同特征维度的相关性,因此MFCC更具优势。
模型
阅读文献:
- An Overview of End-to-End Automatic Speech Recognition[pdf]
主流ASR模型可以分为基于HMM的混合模型和端到端模型两大类。
混合模型
混合模型可以分为:
- 基于HMM-DNN的模型
- 基于HMM-LSTM的模型
HMM-DNN
GMM有很多优点,可以很好地概率分布建模、通过EM算法容易地拟合数据。但是,GMM不能有效地对非线性数据空间的数据进行建模。
DNN具有更强的表达能力,
HMM-LSTM
DNN没有时序建模能力,LSTM增加了对语音时序建模的能力。
端到端模型
下面介绍下端到端模型,大体可以分为三类:
- 基于CTC的模型
- 基于Transducer的模型
- 基于Attention的模型
CTC
Connectionist Temporal Classification(CTC)是一种针对基于深度神经网络的序列任务中输入输出序列不等长问题的准则。
CTC通过前向后向算法自动学习序列的边界信息,无需之前的方法中所需的强制对齐信息,降低了训练代价、减少了累积错误。
对于序列长度,CTC要求输入序列长度大于等于输出序列,在语音识别任务中,输入语音的长度往往都是远大于标注文本的长度的。
由于输入序列长于输出序列,在输出单元集合中增加blank(no label),通过在输出序列中插入blank(-),就可以实现输入和输出的长度对齐。所有可能的对齐的概率之和就是一种对齐标注的概率。
例如,通过插入blank(-),输出序列aab可以对齐为a−ab−、−aa−−abb等若干序列。
Transducer
相比于CTC的目标函数,Transducer没有条件独立性假设,具有更强的建模能力。
相比于CTC的模型结构,增加了文本编码网络(Label Encoder,亦称Prediction Net)和融合网络(Joint Net),对于实时语音识别,更加合适自然。
与CTC类似,前向后向算法可以高效地完成对齐路径的计算。
基于Transducer的模型,从RNN Transducer(RNNT),逐渐演进到Transformer Transducer(TT)、Conformer Transducer(CT)。![]()
Attention
在《Attention is all you need》这篇工作问世后,语音识别也开启了端到端模型的新阶段。
这类模型结构也就是Attention base Encoder-Decoder models(AED),包含了Encoder、Decoder两大模块:
Encoder对声学特征建模,输出声学表示;
Attention机制对Encoder输出做重要程度的加权;
Decoder利用Attention权重和其本身的历史时刻输出“自回归”地输出最终的结果;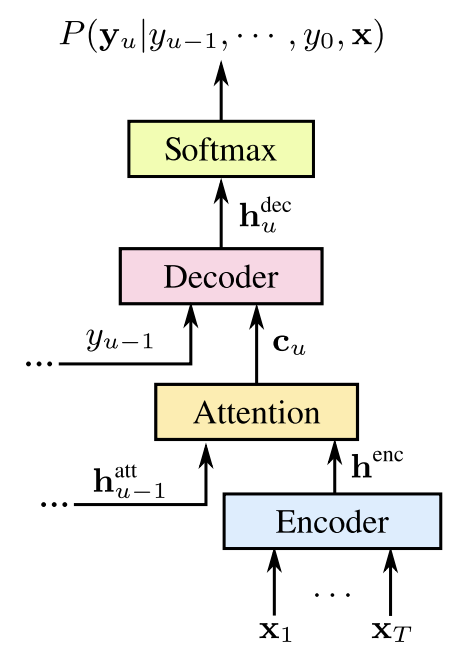
基于AED的模型在建模过程中,引入了Attention机制,更好地对长序列建模,相比于引入了门限机制的LSTM更加“有的放矢”。
AED这类框架中,最初Encoder和Decoder都是多层的LSTM结构,后续提出了非常经典的transformer结构,也就是大家都了解的BERT模型的核心结构。
基于Transformer的结构,后面衍生出很多变种:Conformer、Emformer、Squeezeformer等等。
Attention机制也在不断演变: Generalized Attention, Self-Attention, Multi-Head Attention, Additive Attention, Global Attention,Monotonic Chunkwise Attention(MoChA)
解码
常见的解码方式包括:
- WFST
- beam search