语音大模型概述
写在最前面:访问我的知乎同款文章
背景介绍
语音大模型是什么?
2024年5月,OpenAI的GPT-4o发布,自然流畅的人机对话、强大的语音理解与多样化的语音回复、极低的延迟(0.3秒,与人类相当)让人印象深刻。
这使得研究者们重拾了对语音交互的热情,而且由于大语言模型的加持,语音交互的能力边界大幅提升。理想的语音大模型像人一样,应该具备:高质量语音理解(听)与回复(说)、多轮对话、低延迟、实时对话。
语音大模型(speech large language model, SpeechLLMs)亦有称之为语音对话模型(spoken dialogue models),本文统称之为语音大模型。
1 | |
上面是对语音大模型的一种定义,可以简单地定义为:和人一样能听会说的智能系统。
历史回顾
在大模型时代之前(Pre-LLM Stage),语音技术各个细分方向相对独立,包括语音识别、语音合成、语音增强、语音分离、声音事件监测、说话人识别等等。
随着深度学习的发展(Early-LLM Stage),语音技术开始进入预训练阶段,基于模型和大数据量的语音特征和表示。例如wav2vec、Hubert,大幅提升了模型效果。
进入大模型时代(SpeechLLM Stage),语音技术各个细分方向开始融合,更细分的任务融合成一个任务,例如声音复刻和语音合成融合为Zero-Shot TTS。语音技术开始走向“大一统”:语音大模型。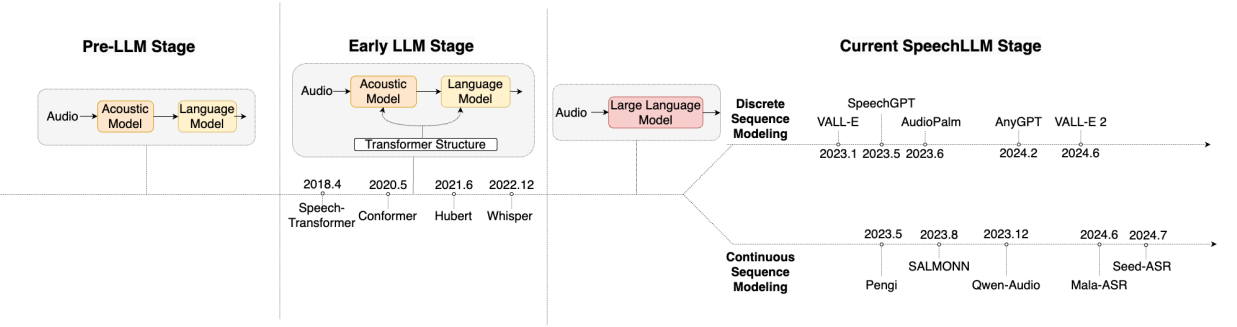
发展趋势
2022年之前,语音技术结合LLMs的工作开始萌芽。
2023年,紧跟LLMs的步伐,语音大模型相关工作开始涌现。
2024年,语音大模型相关研究更加深入,围绕高质量语音、全双工交互等热点难点。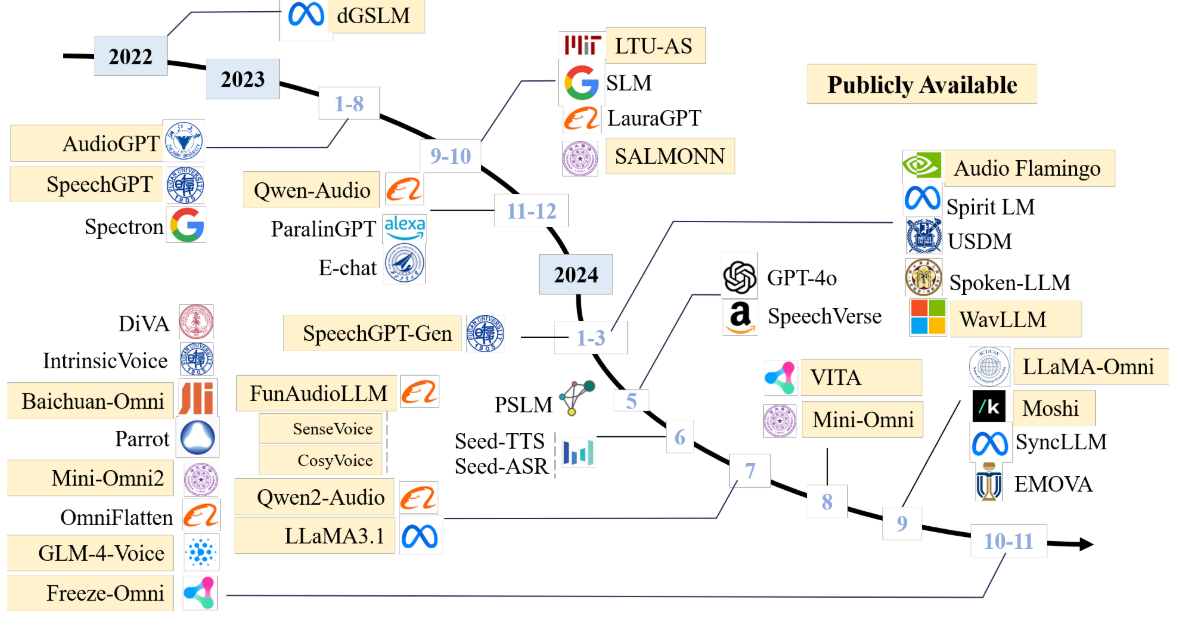
技术路径
在大模型时代之前,实现一个人机语音对话系统是非常繁杂的,涉及多个模块:语音识别、意图识别、对话管理、对话生成、语音合成等模块。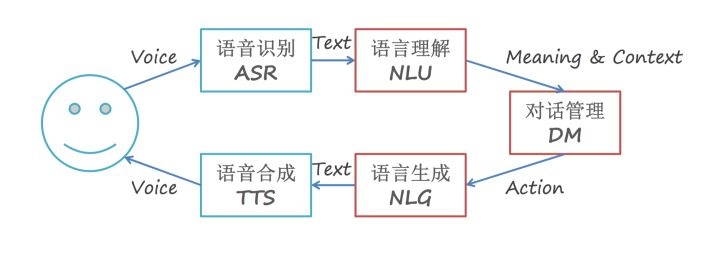
在大模型时代,使用LLMs取代意图识别、对话管理、对话生成等多个模块,让人机对话系统变得简单且更加强大。根据模型是否能够直接理解和生成语音,分为级联、端到端两种技术路径:
- 级联(Cascaded): 语音识别(ASR)、LLM、语音合成(TTS)三部分级联构成。构建成本较低、各模块成熟且相对独立;但是能力潜力小、信息丢失(例如丢失情感信息)、延迟较大。典型例子有AudioGPT。
- 端到端(End-to-end): 一个模型实现语音的输入和输出。系统简单、能力(潜力)强、延迟低;构建成本较大、依赖大量的训练数据。典型例子有Moshi。
下图是级联系统与端到端系统的对比,可以看到两种系统中也分别有两种不同的技术路径,从上到下从完全的级联到完全的端到端。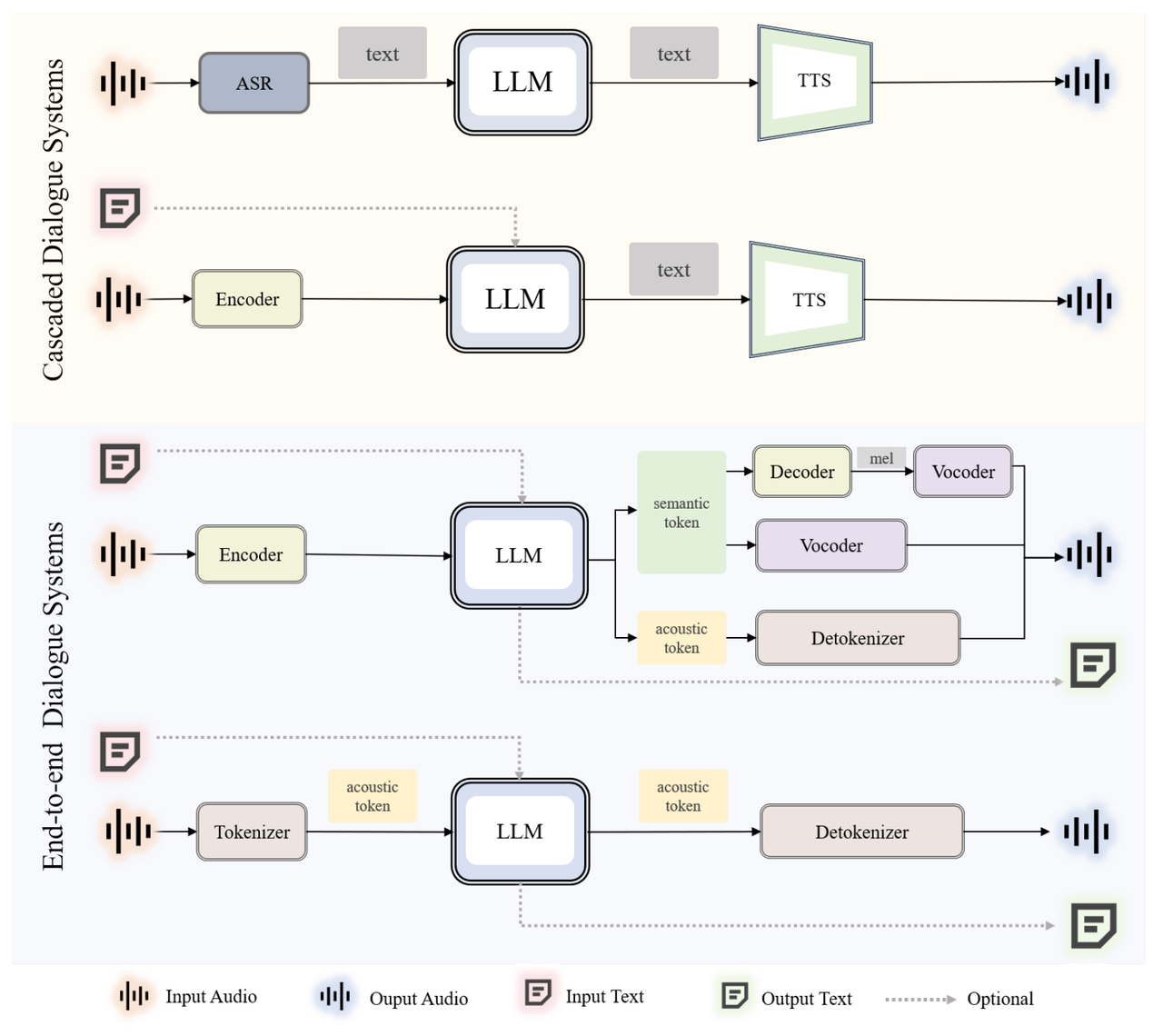
下表是OpenAI的语音模式,GPT-4o是端到端的方式,GPT-3.5和GPT-4都是级联的方式,无论是副语言信息的理解和多样化表达,还是整体的延迟,GPT-4o都大幅领先,使用体验提升明显。
| Feature | GPT-3.5 | GPT-4 | GPT-4o | Moshi |
|---|---|---|---|---|
| Architecture | ASR + GPT-3.5 + TTS | ASR + GPT-4 + TTS | A single end-to-end model | A single end-to-end model |
| Acoustic Information | × | × | √ (speaker, background, emotion…) | √ |
| Expressive Audio Response | × | × | √ (laughter, emotion, singing…) | Multi emotions & styles |
| Latency | 2.8s | 5.4s | 0.32s | 0.23s average (minimum 0.16s) |
模型
这部分先介绍语音大模型的一般模块组成,然后介绍几个典型的语音大模型。
模块组成
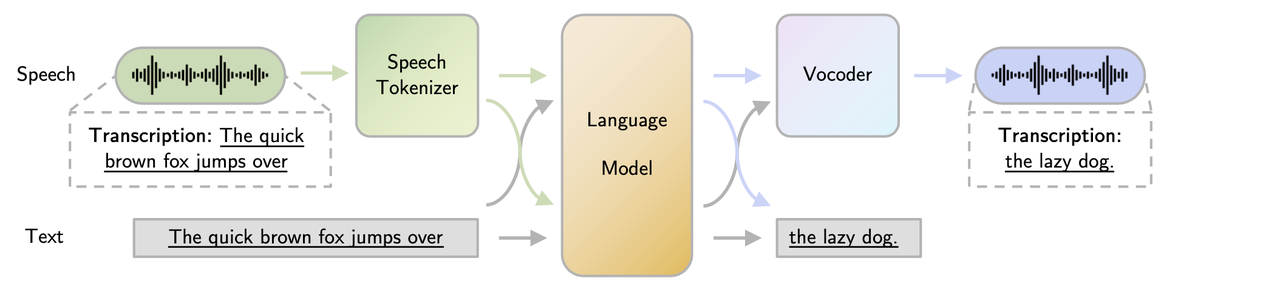
语音大模型一般由三个模块组成:
- 语音编码器(Speech Tokenizer): 有两类典型的Tokenizer,一种是Whisper Encoder,连续空间表示语音;另一种是RVQ结构的Neural Codec Encoder,离散空间表示语音。
- 大语言模型(Large Language Models): 各种语言模型均可。
- 语音合成器(Token-to-Speech Synthesizer): 和上述Speech Tokenizer相对应,前者对应典型的合成器,例如HiFi-GAN等;后者对应Neural Codec Decoder。
SpeechGPT 

SpeechGPT是于2023年5月份,复旦大学提出来的语音大模型。
模块组成
| Speech Tokenizer | LLM | Speech Detokenizer |
|---|---|---|
| Hubert | LLaMA-13B | unit based HiFi-GAN |
模型框架
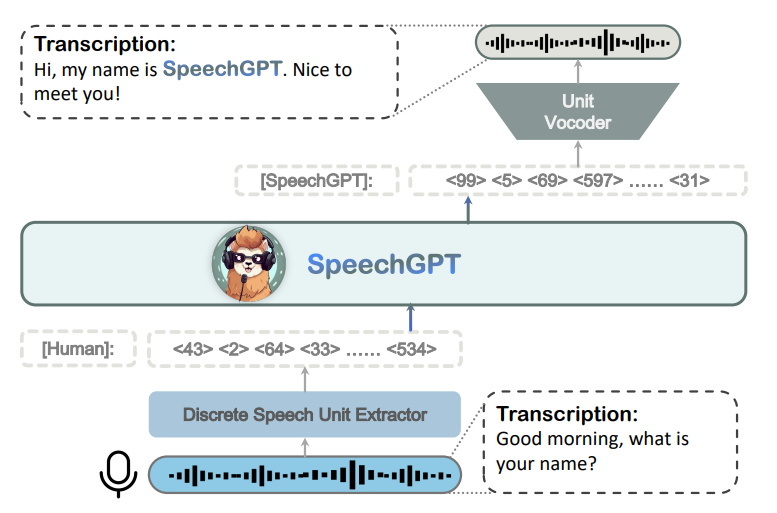
模型训练
- 阶段1:词表扩充&模态自适应。基于6万小时的无标注LibriLight语音数据。
- 阶段2:跨模态指令微调。训练数据包括1万小时GigaSpeech、3千小时CommonVoice、1千小时LibriSpeech。
- 阶段3:Chain-of-Modality Instruction Fine-Tuning。从moss-002-sft-data数据集中挑选的37,969条样本。
分析
- SpeechGPT 是将文本和语音模态融合到LLMs的一次尝试,让LLMs具备了语音理解和生成能力。
- 由于Chain-of-Modality的机制,SpeechGPT无法实现实时交互,只能是半双工交互。
VITA 
VITA是2024年8月由腾讯优图推出的多模态交互模型。
LLaMA-Omni 
LLaMA-Omni 是中科院计算所于2024年9月份发布出来的语音大模型。
LLaMA-Omni用少量的数据和算力成本,构建了LLaMA的语音模态能力。
模块组成
| Speech Tokenizer | LLM | Speech Detokenizer |
|---|---|---|
| whisper-large-v3 encoder | LLaMA-3.1 | unit base HiFi-GAN |
模型框架
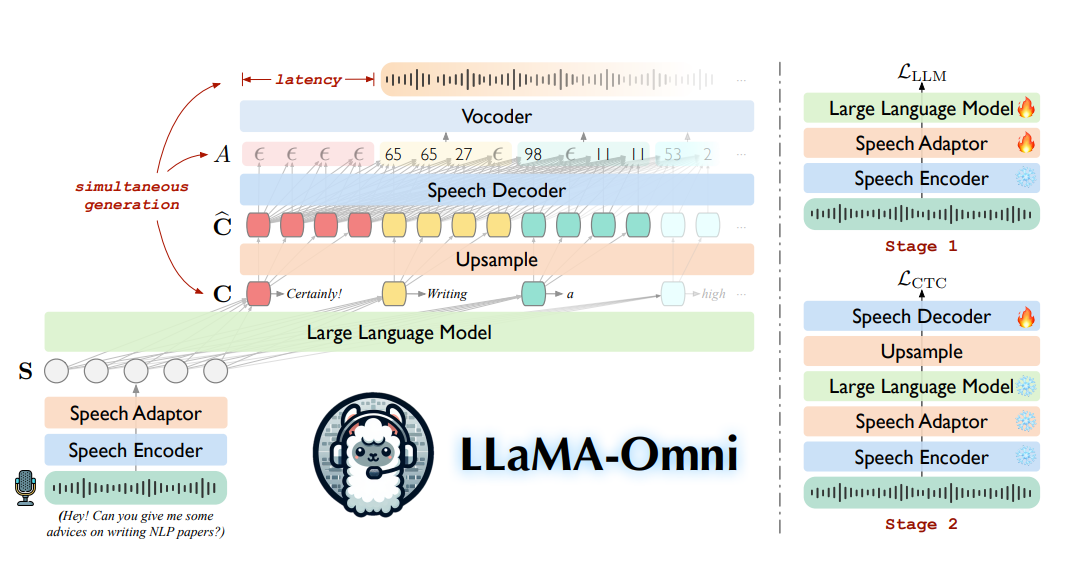
模型训练
LLaMA-Omni采用两阶段训练:
- 阶段1:基于语音指令,生成文本回复。Speech Adaptor、LLMs参与模型训练。
- 阶段2:基于语音指令,生成语音回复。LLMs、Speech Decoder参与模型训练。
分析
- 基于Whisper Encoder融合语音模态,最大程度减少了对LLMs的影响,保持了LLMs本身的能力。较少的训练数据即可实现模型搭建。
- 引入CTC、采用chunk机制合成语音,降低语音回复的延迟。
- 虽然LLaMA-Omni有较低的延迟,但其本质仍是半双工交互方式,不支持打断。
Moshi 
Moshi由法国初创团队Kyutai开发的对标GPT-4o的语音交互模型,7月份发布,10月份公布了技术报告并开源了模型。
Moshi是一个多流的语音到语音的Transformer模型,支持全双工交互。
模块组成
| Speech Tokenizer | LLM | Speech Detokenizer |
|---|---|---|
| Mimi Encoder (12.5Hz x 8 Codebooks) | Helium-7B (As Temporal Transformer) & Depth Transformer (6 layers, d=1024, 16 heads) | Mimi Decoder |
模型框架
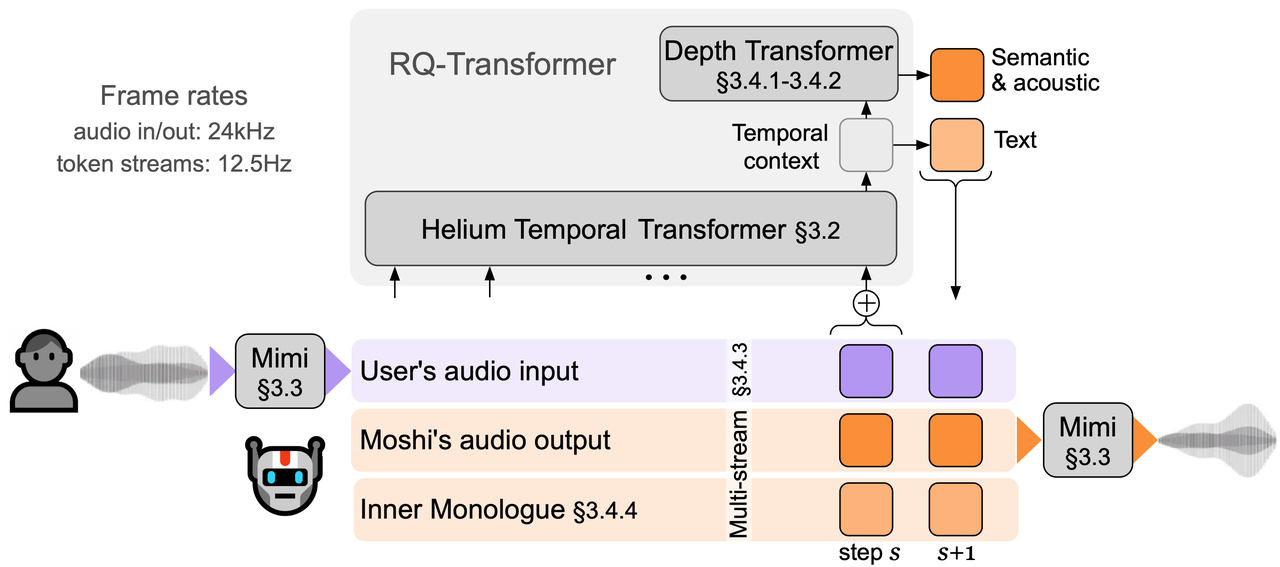
上图是Moshi的模型框架,几个特点:
- Multi-stream:用户语音输入、Moshi语音输出、内心独白。为自然语音交互做好了底层设计,可以同时听和说,支持用户打断。
- Neural Codec:Mimi为了更低比特率、流式编解码、同时包含语义和声学信息,做了针对性设计。
- RQ-Transformer:包含Temporal Transformer和Depth Transformer,TemporaryTransformer处理时间步S,DepthTransformer进一步扩展到多个流。这样,将O(S*K)计算复杂度(S为时间步,K为序列/多流个数)大约减少为O(S)个计算步。
Mimi是Neural Codec,输入24KHz音频,输出12.5Hz的8个Codec,每个取值范围2048,第一个是VQ从WavLM中蒸馏学习语义信息,其他的7个为RVQ。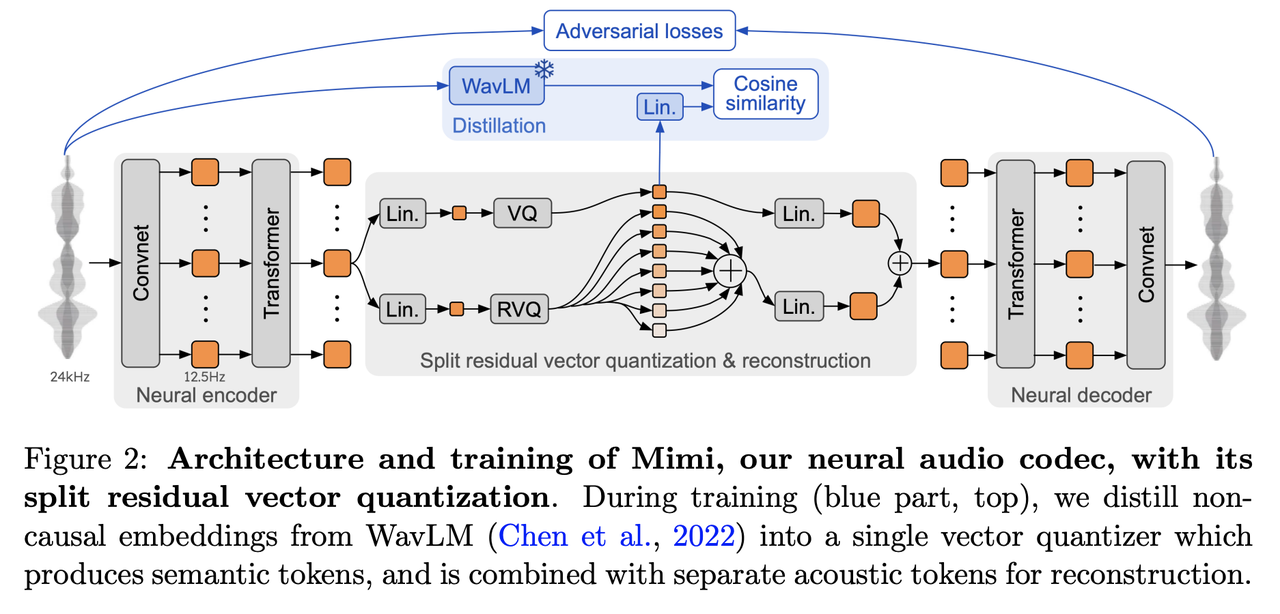
模型训练
- 阶段1:Helium-7B 语言模型预训练。基于大量的文本数据。
- 阶段2:Moshi预训练。单流建模,文本和语音模态对齐。基于Whisper转写的7百万小时弱监督预训练数据。
- 阶段3:Moshi后训练。扩展到多流建模,让模型具备同时听和说的能力。采用了2千小时的电话数据集Fisher,8KHz采样率升采样到24KHz。
- 阶段4:Moshi微调。基于170小时自然对话,学习具有语音交叠的实时对话能力。基于2万小时包含70种说话风格的单说话人合成数据,使得Moshi具备固定音色。
值得一提的是,阶段3的训练,多流建模增加了Moshi的内心独白(Inner Monologue),也就是Moshi 生成语音相对应的文本,对应下图中Moshi stream的Text tokens。内心独白可以提升生成文本和语音的质量。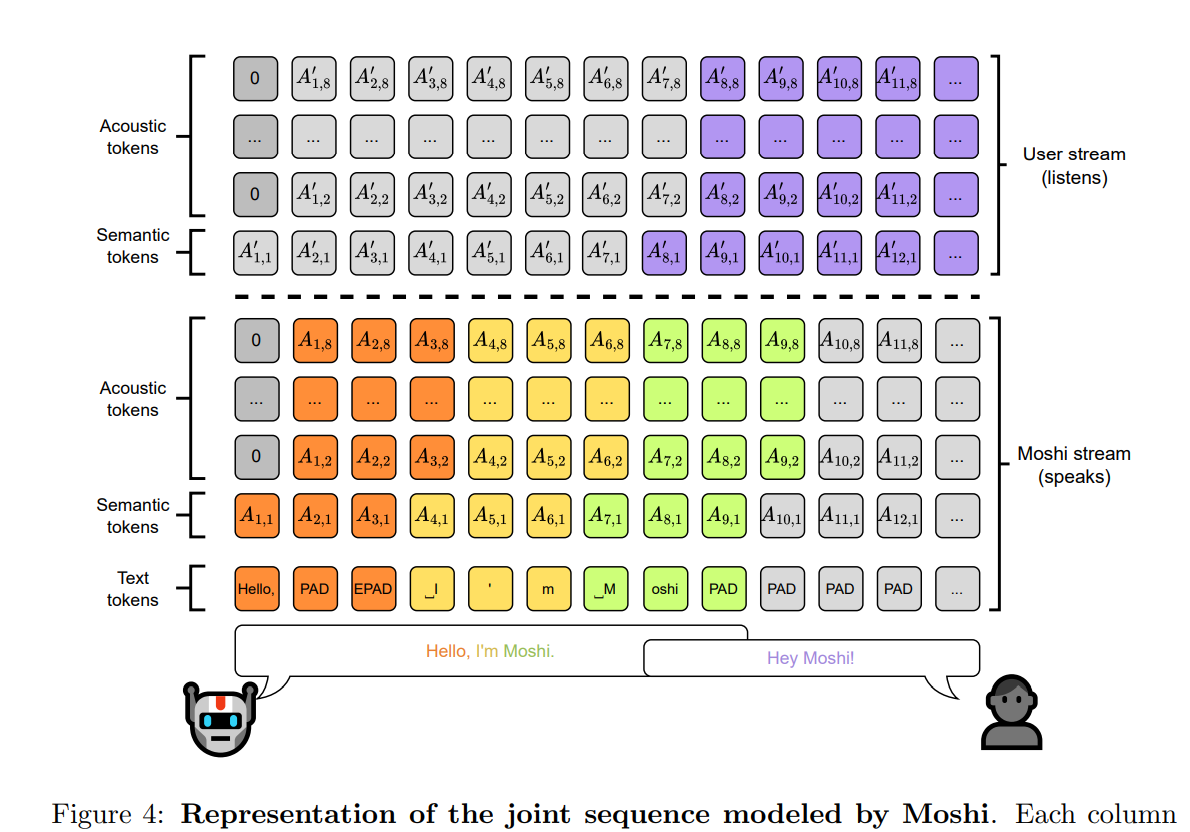
分析
- Moshi对标GPT-4o,实现了多样化语音理解与生成的全双工语音交互。
- Moshi的构建成本很高,需要大量的文本和语音数据,需要大量的算力。
- Moshi的建模方式可以看做是一种‘原生多模态’的建模方式,相比于模态融合,其难度更高,还有很多值得探索。
GLM-4-Voice 
GLM-4-Voice是智谱于2024年10月发布、11月公布技术报告的端到端语音模型。
GLM-4-Voice可以理解中英文语音,进行实时语音对话,并改变生成语音的情感、风格。
模块组成
| Speech Tokenizer | LLM | Speech Detokenizer |
|---|---|---|
| fine-tuned whisper-large-v3 with Quantizer (12.5Hz) | GLM-4-9B-Base | Flow Matching based on CosyVoice + Hifi-GAN vocoder |
模型框架
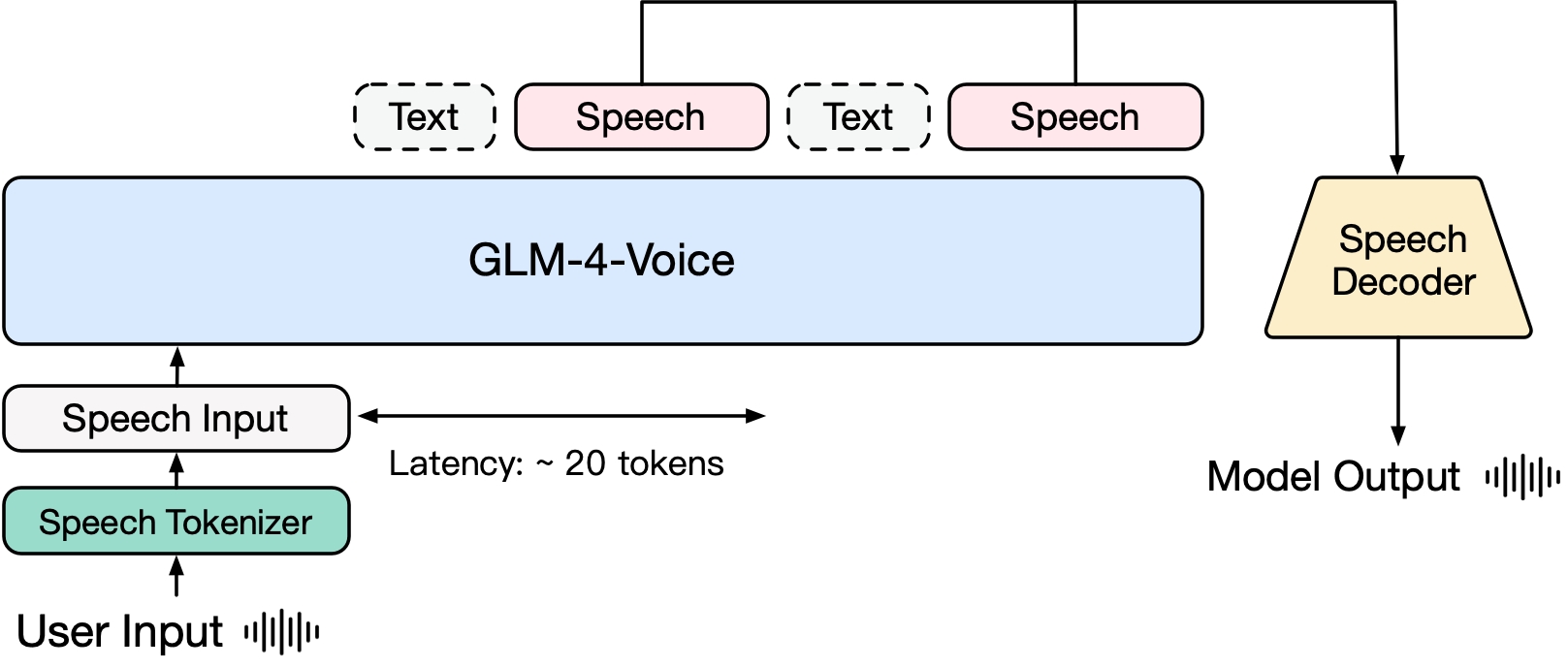
模型训练
- 预训练:文本预训练、语音-文本交替数据预训练,分别对应“根据用户音频做出文本回复”和“根据文本回复和用户语音合成回复语音”两个任务。
- 对齐:输入用户语音,流式输出文本-语音交替内容,语音输出以文本输出为参照保证了回复内容的质量。
分析
- GLM-4-Voice 通过语音-文本交替数据的预训练任务将语音模态和文本模态融入基座模型,这种方式对模态融合有很好的借鉴意义,具体细节可以他们的技术报告。
- GLM-4-Voice支持流式,为此对Whisper Encoder做了流式改造,标准卷积替换为因果卷积、双向注意力替换为因果注意力机制。
- GLM-4-Voice在模型结构侧面没有做全双工(开源的模型),不能同时听和说,而是“半双工”模式。
KE-Omni 

KE-Omni是由贝壳语音团队于2024年12月发布的中英文语音大模型,在VoiceBench上取得优异成绩。
该工作构建了包含6万小时、4万多个说话人的高质量合成语音对话数据集KeSpeechChat,并基于该数据集将LLaMA能力扩展到语音模态。
模块组成
| Speech Tokenizer | LLM | Speech Detokenizer |
|---|---|---|
| whisper-large-v3 encoder | LLaMA-3.1 | Transformer based duration predictor & Transformer based speech unit generator & unit base HiFi-GAN |
模型框架
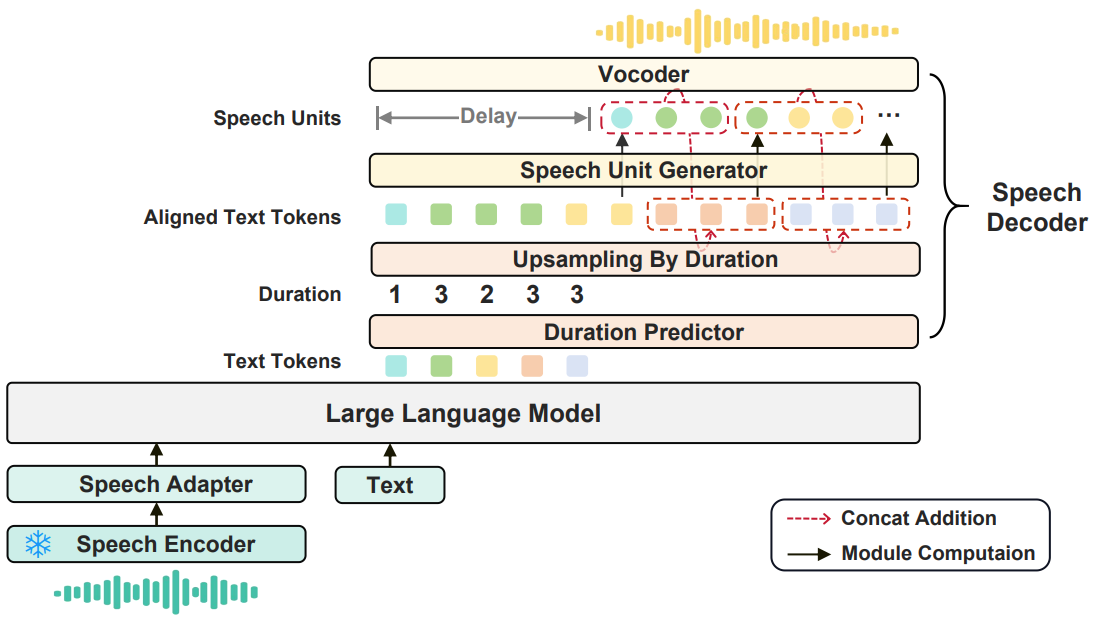
文本对话构建(如下图):引入了大语言模型,对文本指令数据进行口语化的改写。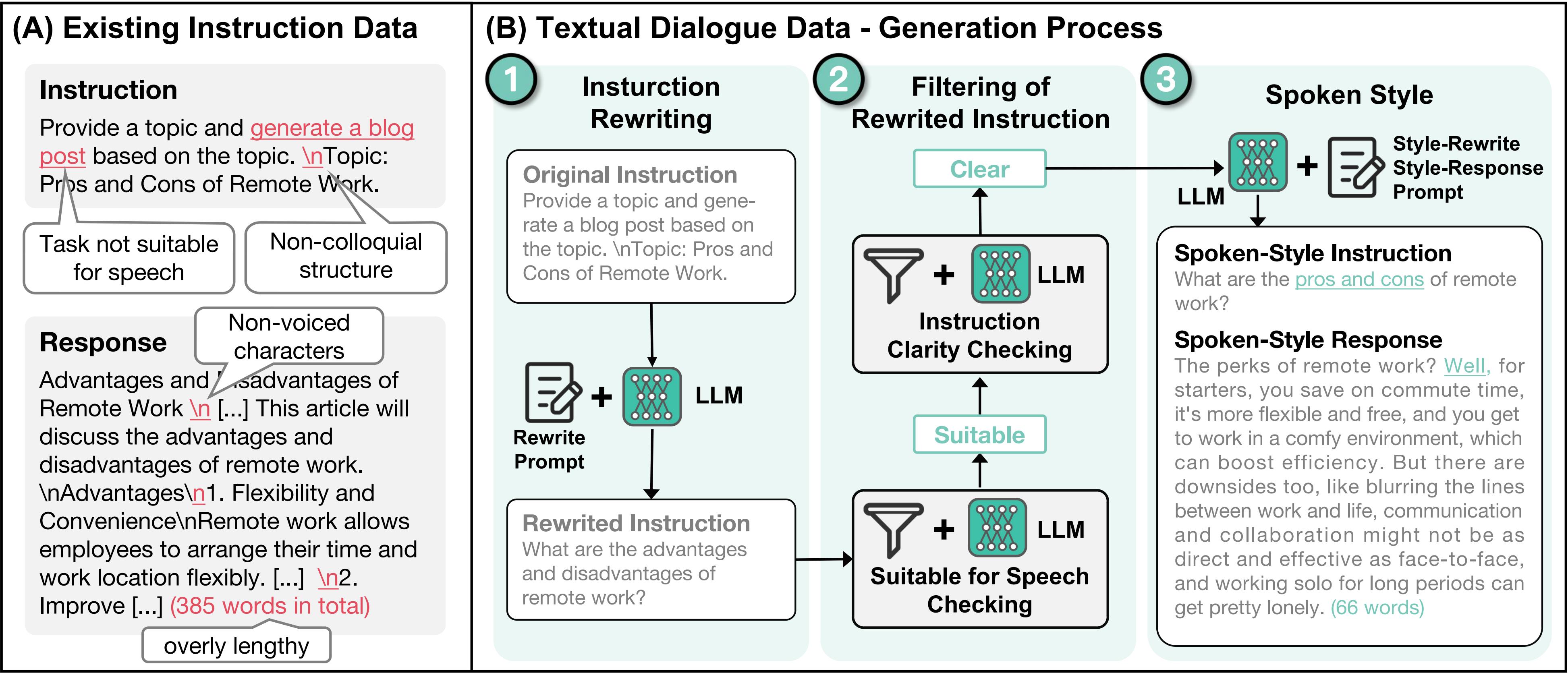
语音对话构建(如下图):提出了一种构建虚拟说话人音库的方法,丰富说话人的多样性。基于CosyVoice合成指定说话人音色的语音对话。对合成的语音对话进行质量筛选过滤。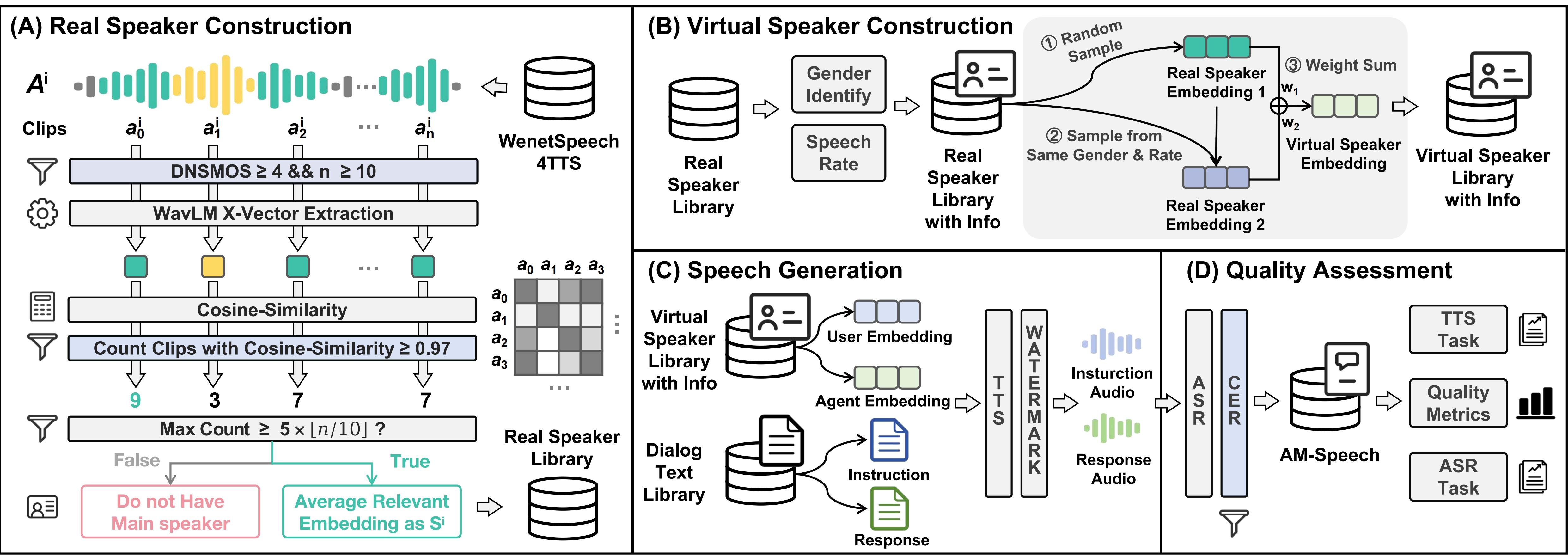
分析
- 该工作提出了大规模高质量语音对话构造方法,并基于数据集在不同的数据尺度上验证了语音大模型的效果。
MiniCPM-o 2.6(2025.01)

MiniCPM-o 2.6 是OpenBMB(清华大学自然语言处理实验室和面壁智能共同发起的开源社区)于2025年1月份开源的多模态大模型,对标GPT-4o,支持图像、语音的理解以及语音的生成。
贡献点
- 实现了多模态实时交互。
- 实现了语音生成的可控,包括情绪、口音、语速等。
模块组成
| Speech Tokenizer(Encoder) | LLM | Speech Detokenizer(Decoder) |
|---|---|---|
| Whisper-medium-300M encoder | Qwen2.5-7B-Instruct | ChatTTS-200M |
模型框架
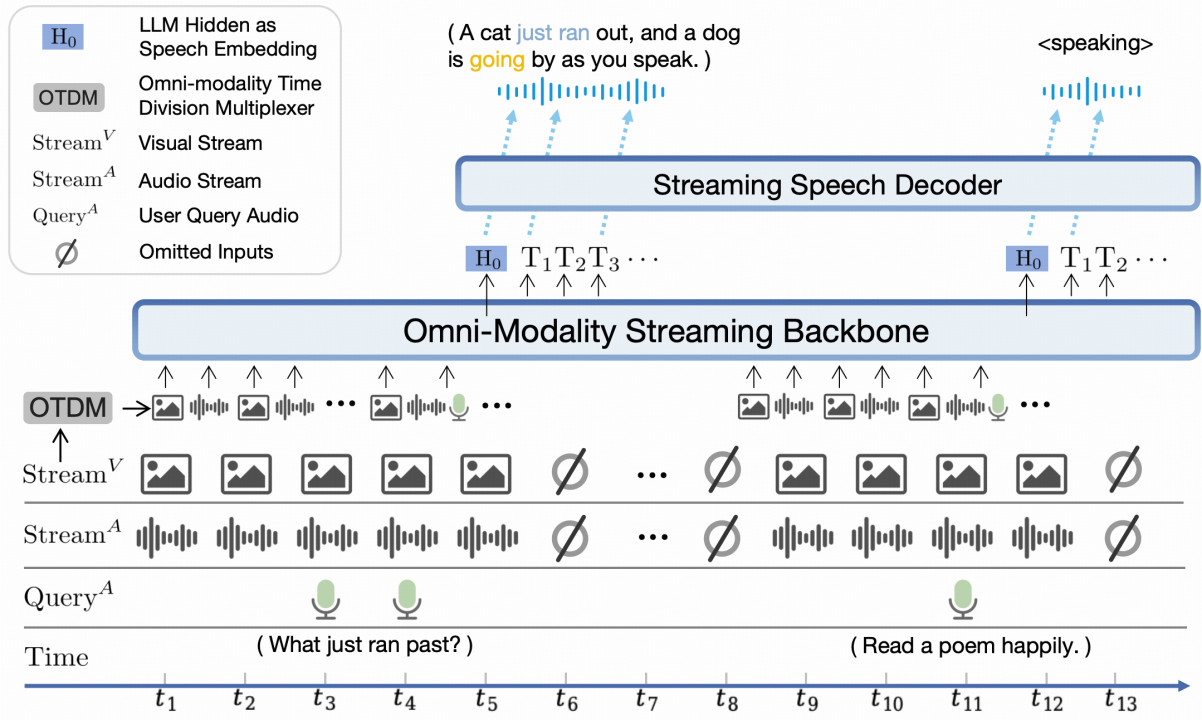
MiniCPM-o-2.6 模型输入语音(麦克风输入、音频文件输入)、视觉(图像、视频),模型输出语音。
为了实现多模态的实时交互,采用了时分复用(Omni-modality Time Division Multiplexing, OTDM)技术,能够及时响应各模态的输入。
模型训练 
MiniCPM-o-2.6采用了三阶段模型训练:
- Pretraining: 首先进行Vision Pretraining,使用图像-文本对对齐视觉和语言模态;然后进行Audio Pretraining,使用语音-文本对对齐语音和语言模态;最后是Omni Pretrainin,基于时分复用机制,融合各个模态。
- Omni SFT:这个阶段基于高质量的多模态数据对模型微调,包括视觉问答、语音理解、语音生成、视频理解等数据类型, 从而实现这些模态上理解和生成能力以及指令遵循能力。
- RLAIF:参考了RLAIF-V的工作,来提升模型的可信性,减少幻觉。
MiDashengLM (2025.08) 


MiDashengLM 是小米大模型团队于 2025 年 8 月推出的开源音频-语言模型(Audio-Language Model),兼具较强的音频理解能力与高效推理性能。
模块组成
| Speech Tokenizer(Encoder) | LLM | Speech Detokenizer(Decoder) |
|---|---|---|
| Dasheng-0.6B | Qwen2.5-Omni-7B | – |
模型框架
MiDashengLM 采用 Audio Encoder + Text Decoder 的 Transformer 架构,训练分为三个阶段,均以“预测下一个 Token”为目标:
- Audio-text模态对齐:通过 Audio Caption任务实现语音与文本表征对齐。
- 预训练:基于 100 万+ 小时语音数据进行大规模建模。
- SFT:在 35 万小时多任务语音数据上优化性能。
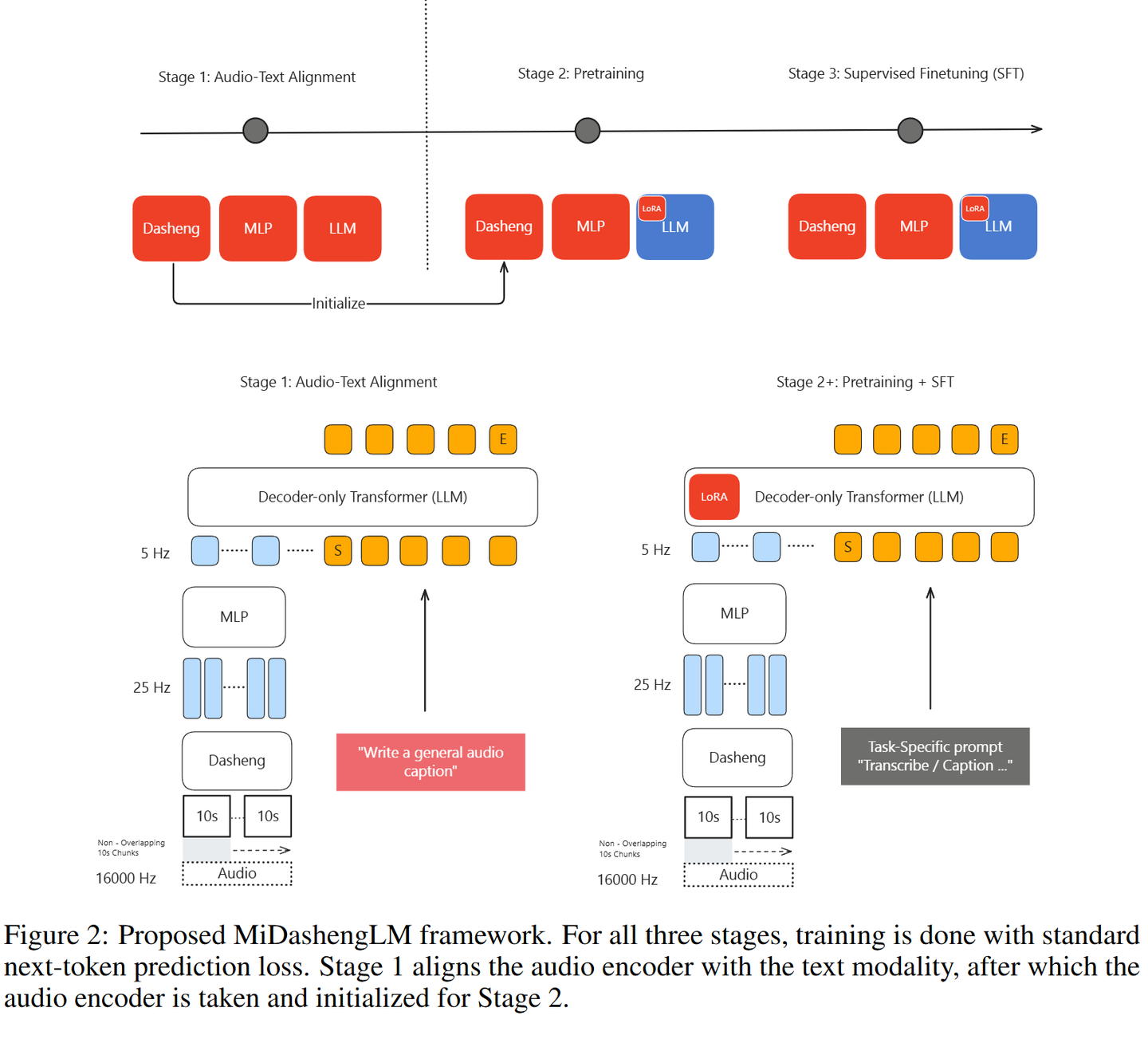
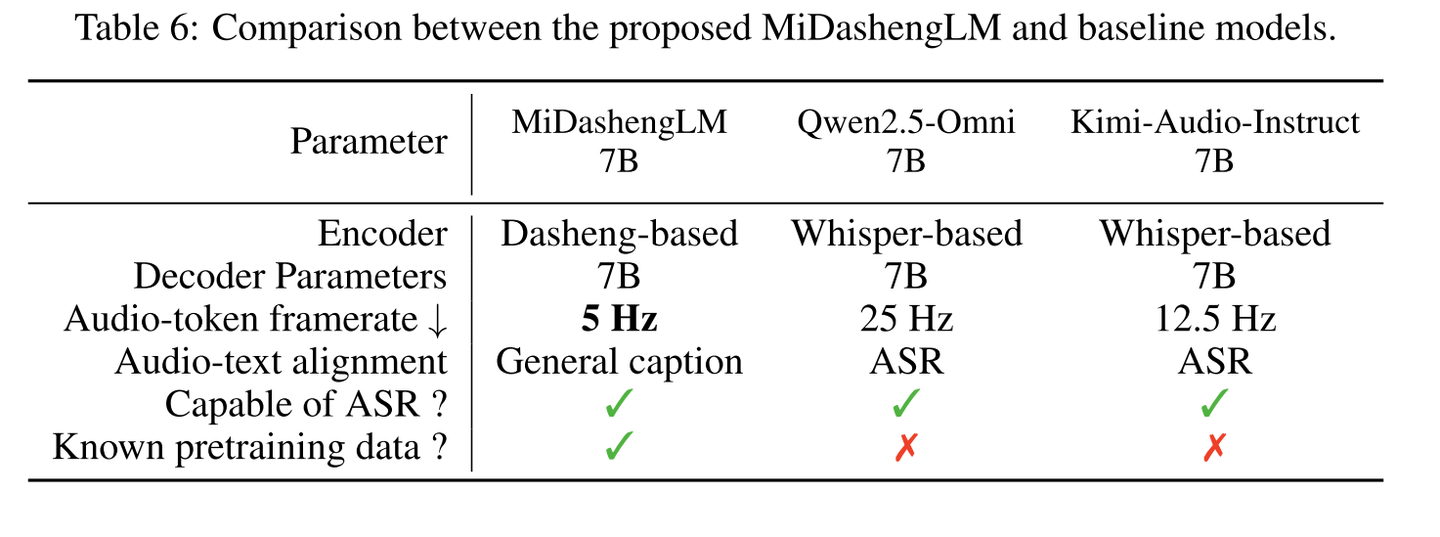
框架对比:
在与 Qwen2.5-Omni 和 Kimi-Audio-Instruct(均为 7B 尺寸)对比时,MiDashengLM 的主要特点为:
- Encoder 差异:MiDashengLM 使用 Dasheng Encoder,而对比模型均使用 Whisper Encoder。
- Token Rate 更低:最低仅 5Hz,显著减轻了语言模型的对齐负担。
- 模态对齐任务不同:采用 Audio Caption 而非 ASR 任务,在保持 ASR 能力的同时,提升了非 ASR 类任务的表现。
小结
MiDashengLM 以 Dasheng Encoder 实现超低 Token Rate,使其在多模态音频大模型中更具优势。通过 Audio Caption 而非传统 ASR 进行模态对齐,不仅保留了语音识别能力,还显著增强了模型在多样化音频理解任务上的泛化性能。例如在Audio Caption评测中,MiDasheng远超baseline: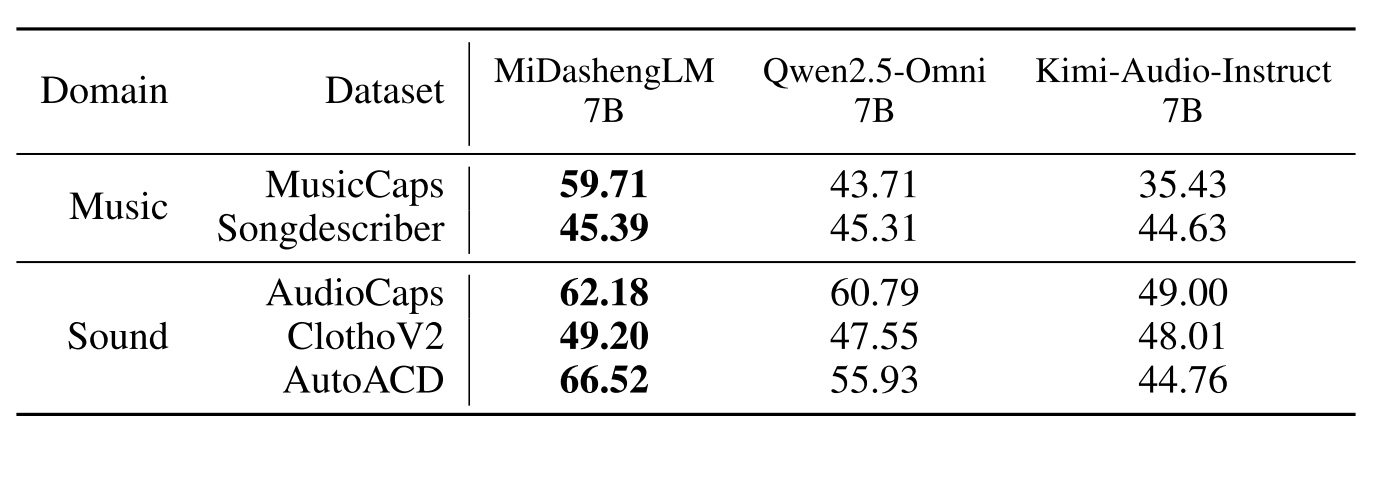
进阶话题
- 音频&音乐
- 全双工交互
- 多模态融合