大模型时代的Audio Tokenizer总结与思考
大模型时代的 Audio Tokenizer 总结与思考
写在最前面:访问我的知乎同款文章
背景
大语言模型拉开了大模型时代的序幕。大语言模型的核心机制是对文本序列建模:通过预测下一个词或字,实现对语言结构和语义的理解与生成。由于文字已经是高度抽象的、符号化的表达,适合直接建模。
随着大模型能力的拓展,多模态融合逐渐成为研究热点。在众多模态中,音频是最重要、最常见的模态之一,广泛出现在语音识别、合成、声纹、增强、音频检索、人机交互等应用中。
然而,相较于文本,音频具有以下特点:
- 连续性强
- 冗余度高
- 信息密度不均衡
这些特性使得音频难以直接建模,需要转化为系统或模型所能接受的表示形式,同时降低冗余信息并保留有用信息。
1 | |
在过去的几十年中,音频的表示形式经历了从人工特征工程到深度学习特征表示再到Neural Audio Codec的演进:
- 传统特征工程:如 MFCC、FBank 等,借鉴人类听觉机制设计,具有实现简单、计算高效等优势,但表达能力有限。
- 深度学习表示:如自编码器(AE)、变分自编码器(VAE)的 latent 向量,或是基于 Transformer 的 HuBERT、Wav2Vec 等模型,在捕捉语音中的高层语义结构上表现更强。
- Neural Audio Codec:最近成为主流方向。这类方法将音频压缩为离散 token 序列,不仅方便大模型以自回归方式建模,还支持语音的高质量重建,使得音频的理解与生成任务可以统一建模。
1 | |
总览
对目前出现的 Audio Tokenizer 进行整理,并详细列出码本数、码率等特性,便于对比分析。
| Tokenizer | 时间 & 作者 | 码本数 | Token Rate (Hz) | Bit Rate (kbps) | 采样率 (kHz) | 训练数据 | 应用 |
|---|---|---|---|---|---|---|---|
| SoundStream | 2021.07 Google | 8~80 | 75×码本数 | 3~18 | 24 | LibriTTS、音乐 | AudioLM |
| Encodec | 2022.10 Facebook | 2,4,8,16,32 | 75×码本数 / 150×码本数 | 1.5,3,6,12,24 / 3,6,12,24 | 24 / 48 | Common-Voice, DAPS, Jamendo, AudioSet, FSD50K | VALLE |
| AudioDec | 2023.05 Meta | 8 | 1280 | 12.8 | 48 | Valentini | - |
| AcademiCodec | 2023.05 北大 & 腾讯 | 4 | - | 2,3 | 16 | LibriTTS, VCTK, AISHELL | - |
| DAC | 2023.06 Descript | - | - | - | - | - | - |
| SpeechTokenizer | 2023.08 复旦 | 8 | - | 4 | 16 | LibriSpeech | SpeechGPT, AnyGPT |
| Funcodec | 2023.09 阿里 | 32 | - | 16 | 16 | LibriTTS、25K hours others | LauraGPT |
| CosyToken | 2024.07 阿里 | 1 | - | - | 16 | 13wh ZH、3wh EN、5kh Yue、4.6kh JP、2.2kh KO | CosyVoice |
| Xcodec | 2024.08 港科大 & Microsoft | 8 | - | 4 | 16 | LibriSpeech | - |
| WavTokenizer | 2024.08 浙大 | 1 | 40, 75 | 0.5, 0.9 | 24 | LibriTTS、VCTK、CommonVoice、LibriLight 共80k小时 | - |
| SemantiCodec | 2024.05 萨里大学 & 上海交大 | - | 25,50,100 | 0.31~1.40 | 16 | GigaSpeech, VoiceFixer, Million Song, MedleyDB, MUSDB18, AudioSet | - |
| Mimi codec | 2024.10 Kyutai | 8 | - | 1.1 | 24 | - | Moshi |
| Stable Codec | 2024.11 Stability-AI | 3 | 25, 50 | 0.4, 0.7 | 16 | - | |
| Step-Audio-Tokenizer | 2025.02 stepfun-ai | - | - | - | - | - | - |
| BiCodec | 2025.03 SparkAudio | 1 | 50 | 0.65 | 16 | LibriSpeech, Emilia-CN, Emilia-EN | Spark-TTS |
| ALMTokenizer | 2025.04 港中大 | 3 | 37.5 | 0.41 | 24 | LibriTTS, MLS, AudioSet, Million Song | - |
| higgs-audio-v2-tokenizer | 2025.07 BosonAI | 8 | 25×8 | 2.0 | 24 | - | higgs-audio |
Neural Audio Codec 模型详解
SoundStream (2021.07) 

SoundStream 是由 Google Research 的 Neil Zeghidour 等人在 2021 年提出的,可以说是 Neural Audio Codec 方向的开山之作。值得一提的是,Neil Zeghidour 也是 Moshi 的主要作者,在音频建模领域贡献颇多。
SoundStream 的提出标志着一种新范式的开始:利用端到端神经网络对音频进行压缩,并生成离散化的 token 表达,以支持下游建模任务,特别适合与大语言模型对接。
模型架构
整体架构采用 编码器-量化器-解码器(Encoder-RVQ-Decoder) 的方式,具体来说:
- Encoder 将原始波形压缩为低维表示;
- Residual Vector Quantization(RVQ) 将连续表示离散化为多组 token;分多级量化器,每级负责编码残差信息,逐步逼近原始向量。
- Decoder 从离散 token 重建出原始音频。
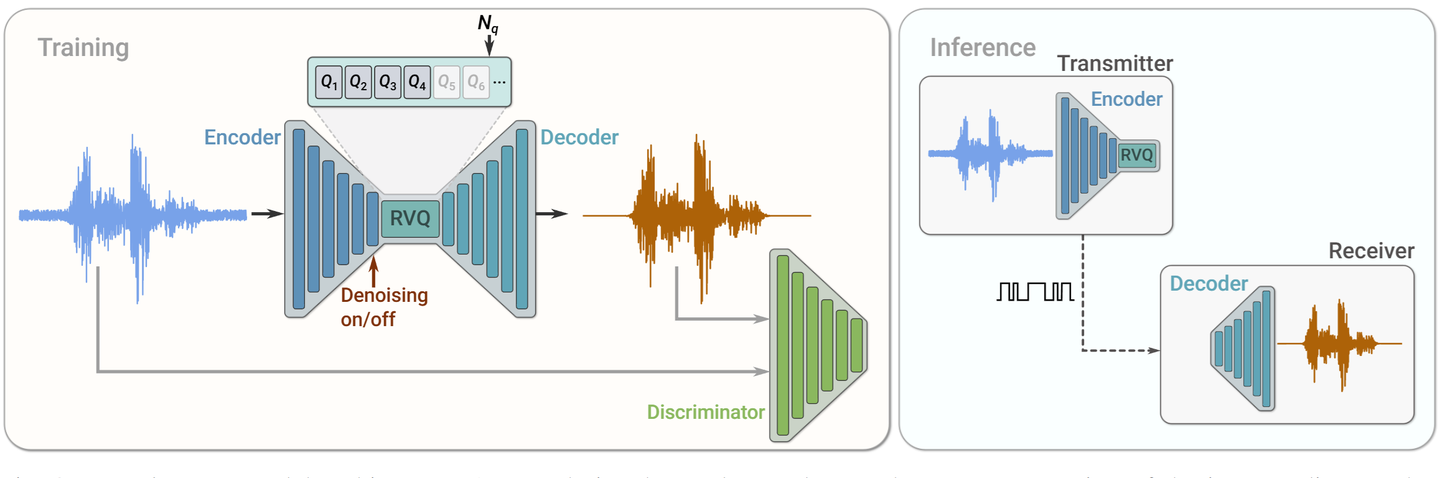
RVQ算法
在 Neural Audio Codec 中,最关键的一步是如何将连续信号离散化为 token 表示。SoundStream 使用了 Residual Vector Quantization(RVQ) 技术,其主要思想是分多级量化器,每级负责编码残差信息,从而逐步逼近原始向量。更多详细解读
效果
SoundStream 在语音重建质量上优于传统压缩方法(如 Opus),尤其在低比特率下依然保持不错的主观听感。其强大的表示能力也使其适用于后续的语音合成、生成、编辑等任务。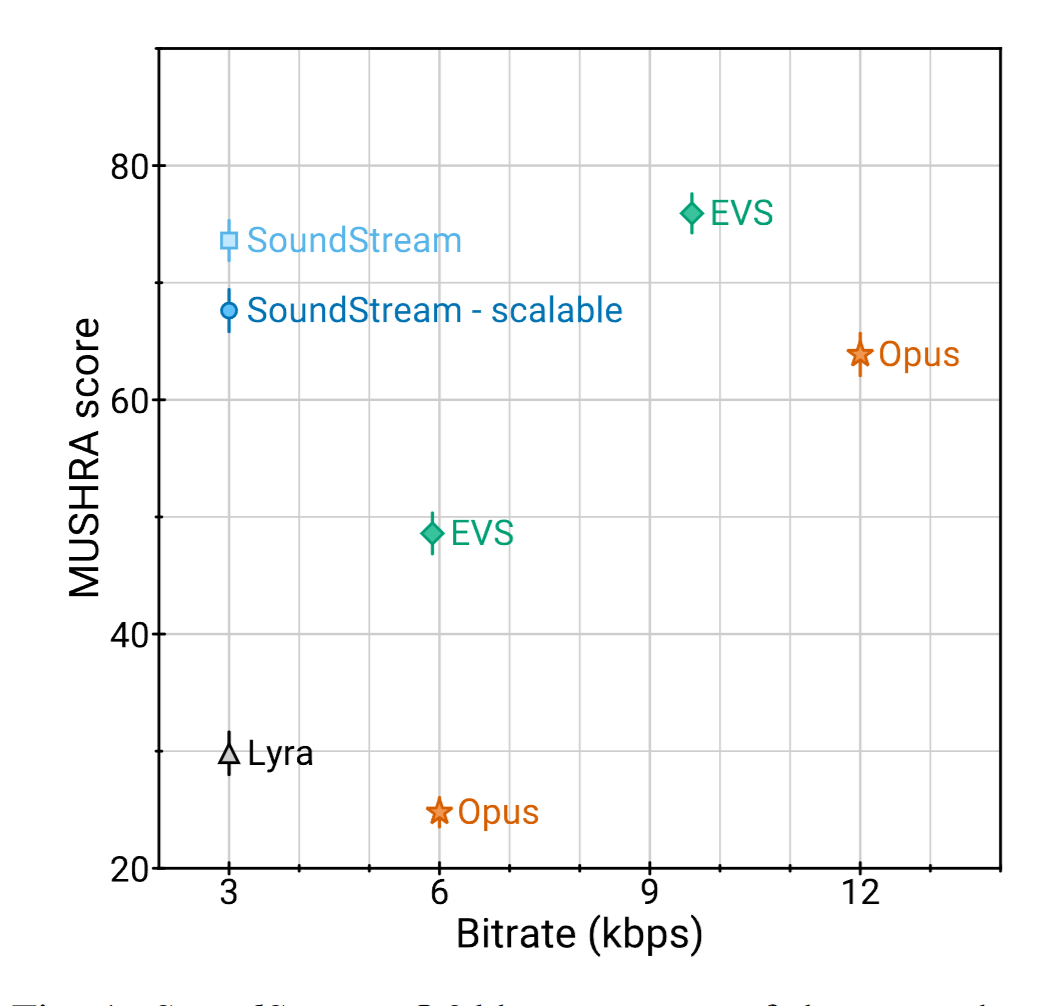
小结
SoundStream 是 Neural Audio Codec 方向的奠基之作,不仅首次系统性地提出神经音频压缩框架,也确立了 RVQ 作为音频离散化的核心技术路径。虽然机制并不复杂,但在实际中非常高效,影响了后续整个音频tokenization领域的发展。
EnCodec(2022.10) 


EnCodec 是 Meta AI 于 2022 年提出的 Neural Audio Codec 模型,作为对 SoundStream 框架的延续和改进,它同样采用了 Residual Vector Quantization(RVQ) 技术,并在音频质量、适用范围和开源支持方面做了全面升级:
- 多采样率支持:EnCodec 同时支持 24kHz 和 48kHz 音频信号,覆盖语音和高保真音频等不同应用场景;
- 多比特率可调:提供从 1.5 到 24 kbps 的多个比特率选项,适用于不同带宽和重建质量的需求;
- 延续 RVQ 框架:与 SoundStream 一样,EnCodec 使用多层残差量化器将音频编码为离散 token 序列,使得大模型可以直接用于建模;
- 开源可复现性强:Meta 提供了完整的代码、模型权重与示例脚本,极大地推动了社区在音频离散化方向的研究与落地。
- 影响力广泛:微软提出的端到端语音合成模型VALLE,直接采用 EnCodec 生成离散语音 token;Meta 的音乐生成模型MusicGen,也使用 EnCodec 作为音乐 tokenization 的底层模块;
模型架构
EnCodec 仍采用编码器-量化器-解码器的标准框架。相比 SoundStream,EnCodec 在编码器与解码器的架构上进行了优化,引入了更深层次的卷积模块与归一化技术,提升了压缩后的重建质量。
小结
EnCodec 在保持高压缩效率的同时提供更高的可控性和更好的重建质量,是 Neural Audio Codec 技术的重要里程碑。其高质量开源实现加速了音频 tokenization 技术的工程化应用,也为大模型时代的多模态建模奠定了坚实基础。
SemantiCodec (2024.05) 


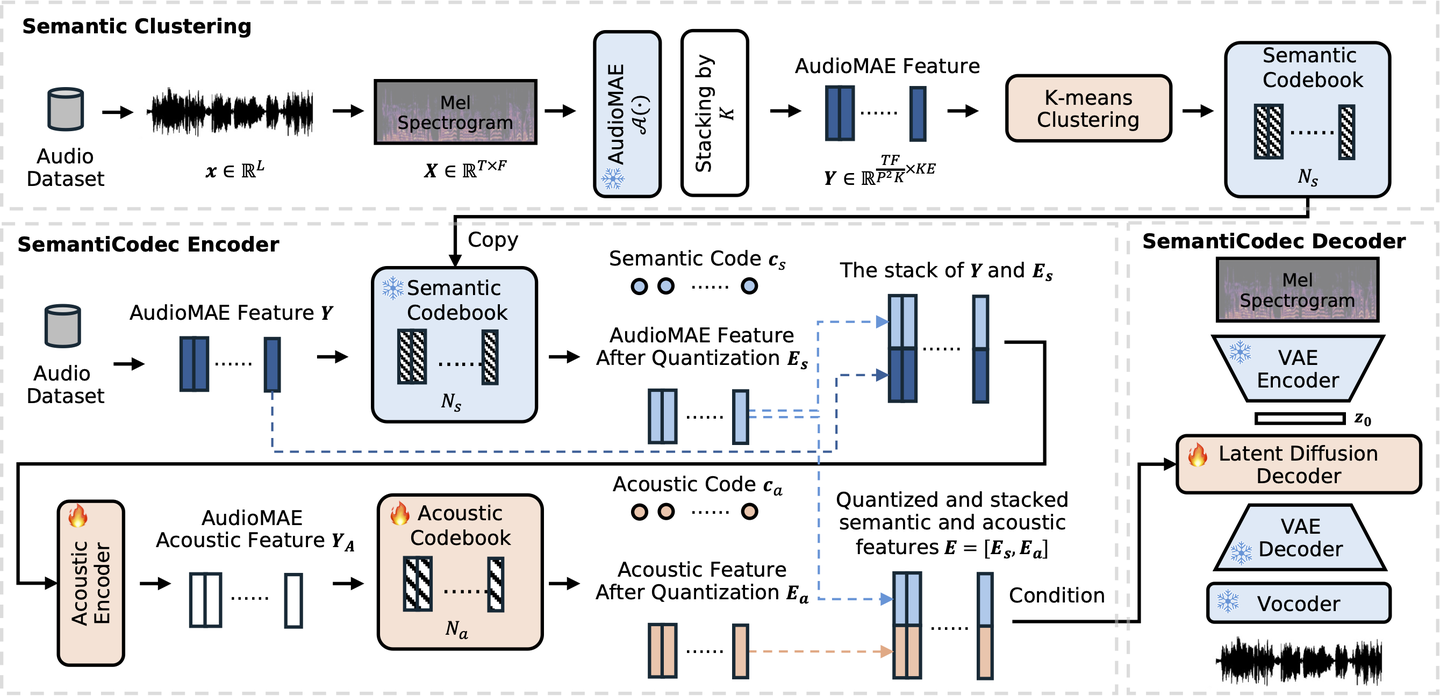
SemantiCodec 是由萨里大学与上海交通大学联合提出的一种极低码率的开源 Audio Tokenizer,专为语义理解与生成任务设计。其核心创新在于显式建模语义与声学特征的联合表示,以支持更强的语义能力与灵活的压缩率选择。
强语义建模能力:通过引入 AudioMAE 语义嵌入,提升离散表示的语义表达力;
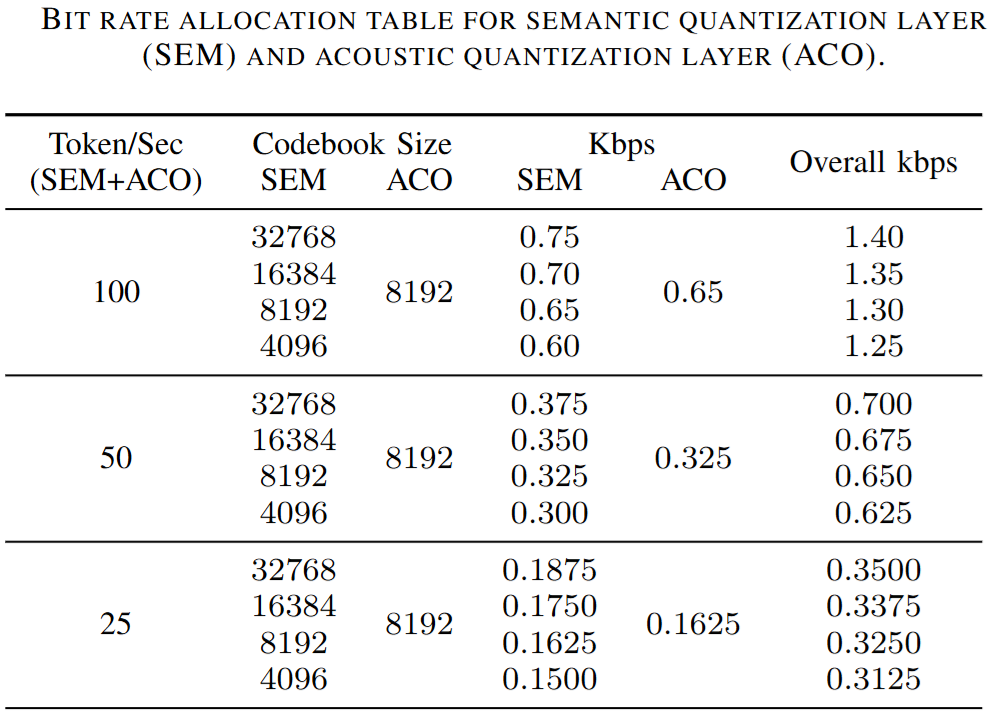
丰富的 TokenRate 与 BitRate 选择:支持 25、50、100 tokens/s 三档 TokenRate,对应比特率范围为 0.31~1.43 Kbps,便于适配不同带宽和任务需求。具体如下图所示:
模型架构
- 语义编码:首先从输入音频中提取 AudioMAE 嵌入,并通过 K-Means 聚类量化为语义表示 $E_s$;
- 声学补全:将原始音频帧 $Y$ 与语义表示 $E_s$ 拼接输入 Residual Encoder,提取细粒度声学信息;
- 向量量化:上述声学向量经 VQ 模块量化为 $E_a$;
- 融合表示:最终音频表示 $E$ 由 $E_s$ 与 $E_a$ 拼接构成,用于音频重建;
- 生成器:使用 Latent Diffusion Model 在条件表示 $E$ 上进行音频生成。
效果
在主观音质评估基准 MUSHRA 上,SemantiCodec 明显优于 Encodec、Descript 等方法,尤其在低码率条件下表现出更好的听感质量。
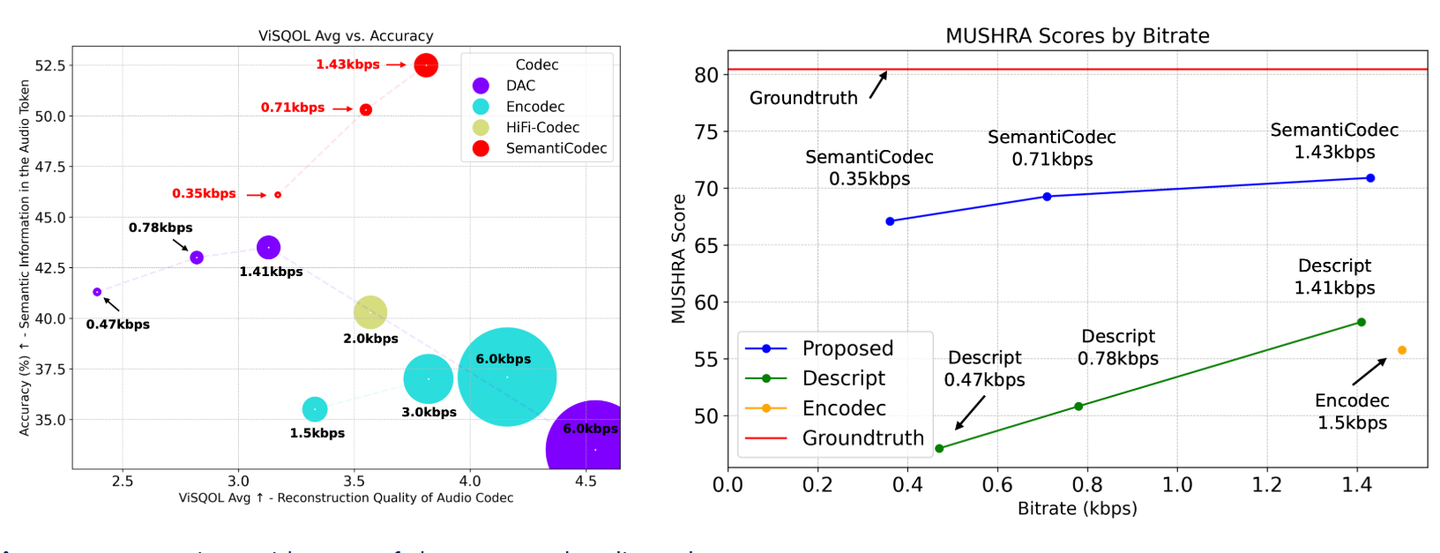
小结
SemantiCodec 是一款支持 极低 BitRate 与 TokenRate 的开源 Audio Codec,具备可调节压缩粒度、显式语义建模、高保真语音重建等特点,非常适合用于语音理解、多模态交互等大模型应用场景。
WavTokenizer (2024.08) 


WavTokenizer 是浙江大学联合阿里巴巴于 2024 年 8 月提出的一种面向大语言模型的 Neural Audio Codec,后被 ICLR 2025 接收。该方法以约 8000 小时多语种语音数据训练为基础,核心目标是更好地服务于多模态大模型需求。其设计强调两大核心指标:
- 更高的压缩率:支持 40 或 75 tokens/s 的极低 Token Rate,显著减少下游模型的计算开销。
- 更丰富的语义表达:在主观语义评估中取得 SOTA 表现,提升了生成任务中的理解与控制能力。
模型框架
- Encoder:基于卷积网络将输入音频编码为潜在连续特征表示$Z$
- A single quantizer:将 $Z$ 单层量化,得到离散表示 $Z_g$
- Decoder:将 $Z_g$ 重构成语音信号
效果
WavTokenizer重构语音的UTMOS得分达到SOTA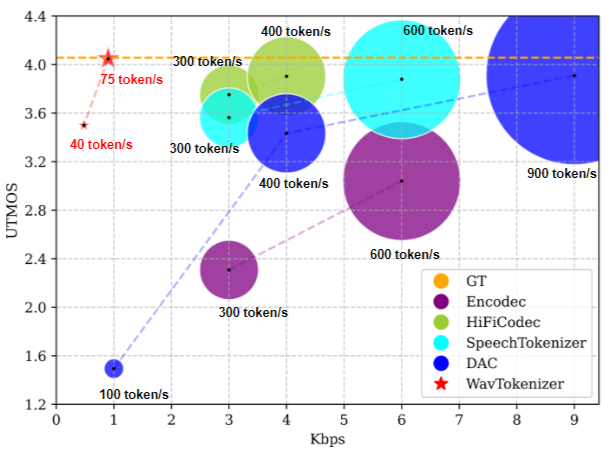
小结
WavTokenizer 具备极低的 Token Rate(最低可达 40 tokens/s),高度契合多模态大模型的建模需求。同时,依托大规模语音数据训练,其离散表示包含丰富的语义信息,支持语义理解与语音生成双重任务,在语音重构质量上也达到了当前最优水平。
Stable Codec (2024.11) 


Stable Codec 是 Stability AI 于 2024 年 11 月发布的开源 Neural Audio Codec,专为大模型时代的语音建模需求而设计。该模型在超低码率(400bps / 700bps)下仍保持高保真度重建,为多模态大模型中的音频输入提供了极具竞争力的离散表示方案。
模型架构
- Encoder / Decoder:基于自注意力机制的对称结构;
- Finite Scalar Quantization(FSQ):替代传统 RVQ 的新型量化方式,采用固定范围标量量化,将连续表示压缩为离散 token。FSQ 简洁高效,推理速度快,且更适用于低码率场景;
- 极低码率支持:支持 400bps、700bps 等超低比特率设置,在极限压缩下仍保持较高音质。
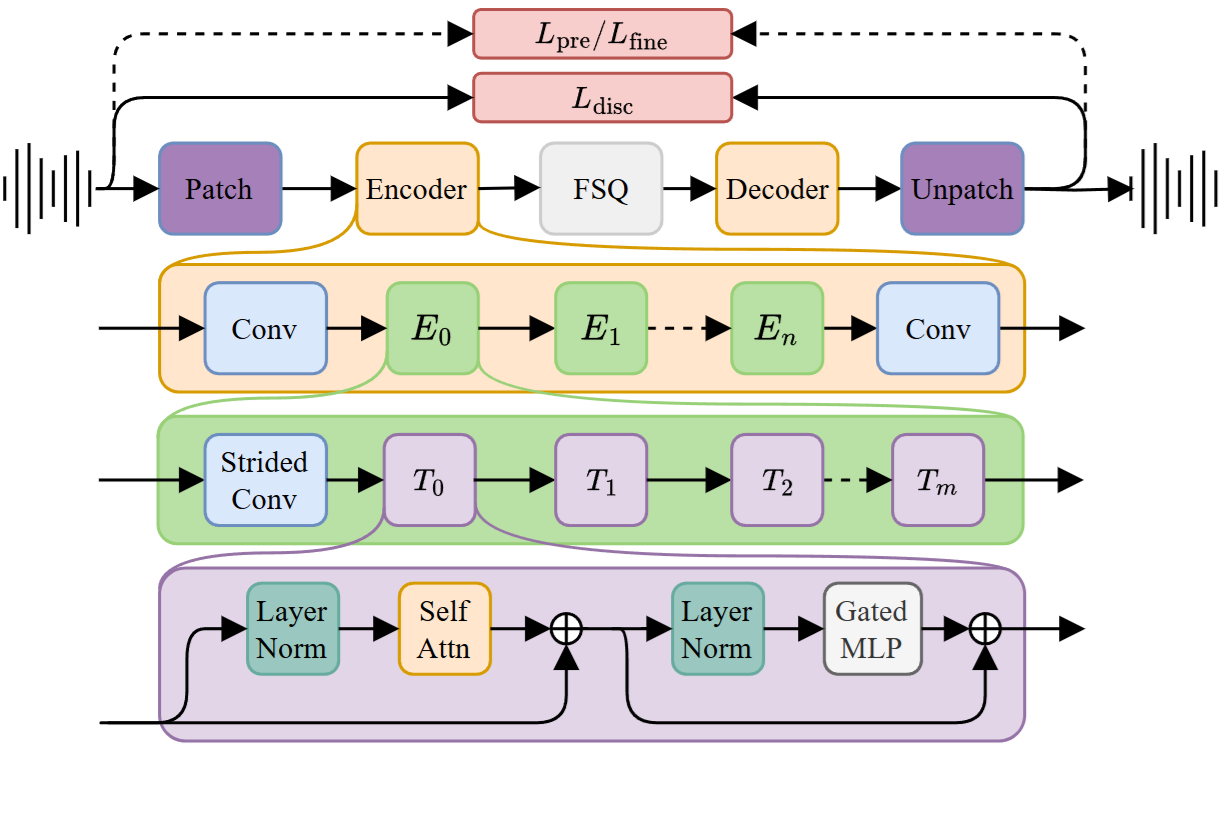
FSQ V.S. VQ
这里提到了FSQ,为了有更直观的认识,这里列出二者的差异。
下图举例对比FSQ和VQ的差异:
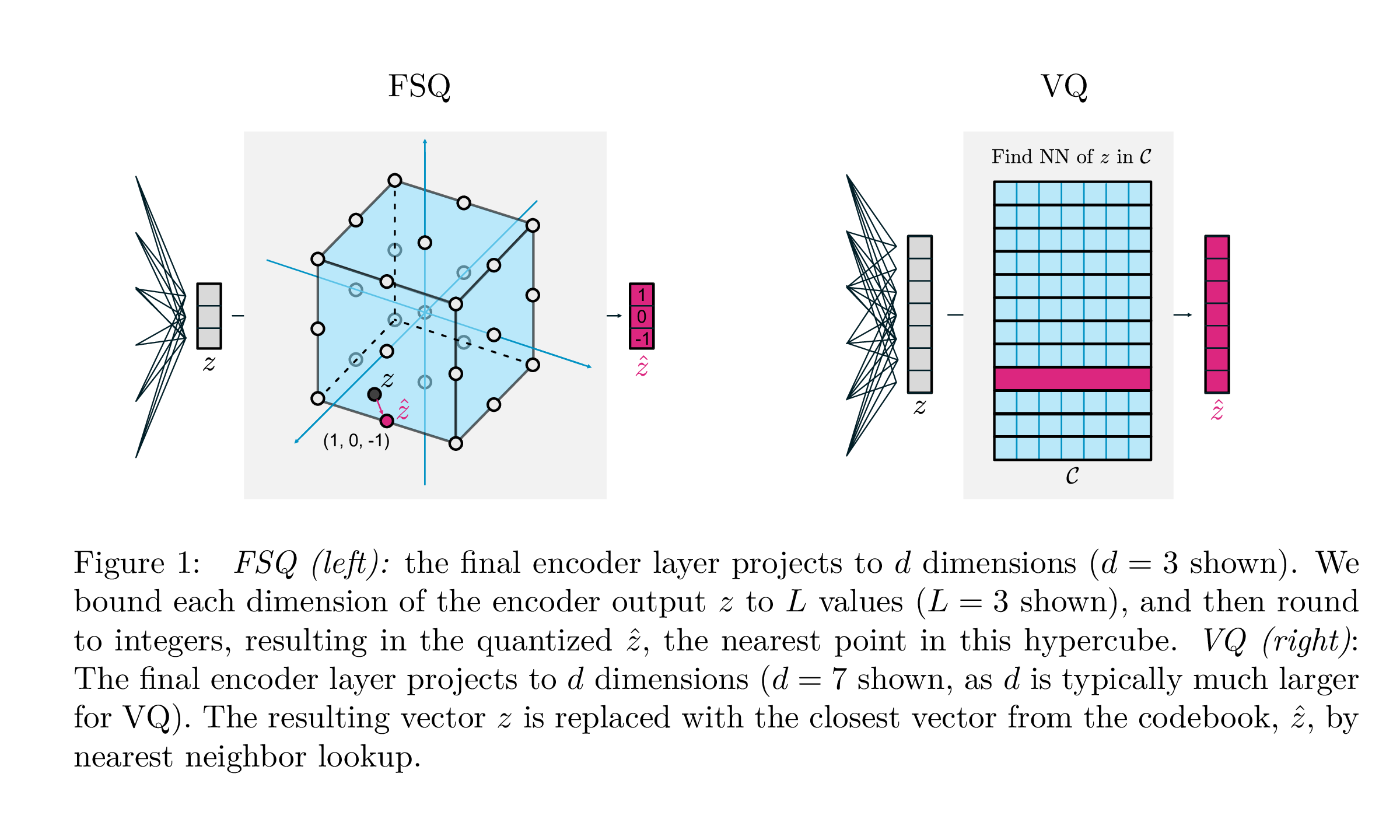
下表从不同维度详细对比FSQ和VQ的差异:
| 属性 | FSQ | VQ |
|---|---|---|
| 量化方式 | round(f(z)) | argmin_c || z-c || |
| 量化单位 | 每个维度单独量化 | 整个向量最近邻 |
| 编码方式 | 标量量化(整数) | 码本索引 |
| 并行性 | 高(可并行) | 低(需查找) |
| 表达粒度 | 粗,从坐标轴限制(维度独立) | 细,全局表示能力较强(跨维度) |
| 实现复杂度 | 低 | 高 |
整体而言:
- FSQ 是把高维输出按坐标轴切割成格子,每维分别处理;
- VQ 是把输出投到一个高维超立方体的码本格点上,整体处理。
效果
在MUSHRA 主观评测中,Stable Codec 的表现优于其他同类模型如 Mimi 和 SemanticCodec,其音质在主观评分中接近真实语音(Ground Truth)。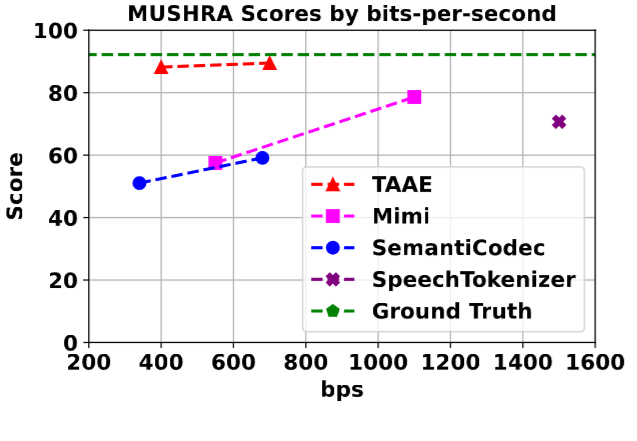
小结
Stable Codec 凭借其超低码率、高音质、Transformer 架构与 FSQ 创新量化方式,是语音大模型中的潜力型 Audio Tokenizer 方案。其设计思路代表了 Neural Audio Codec 向更轻量、更高效、更大模型友好方向的发展趋势。
XY-Tokenizer (2025.07) 


XY-Tokenizer是复旦大学邱锡鹏团队推出的MOSS-TTSD项目中提出的离散Tokenizer。
实现了统一建模语音的语义和声学信息,支持低比特率(1 Kbps)与低帧率(12.5Hz),适用于高效语音生成任务。
模型框架
模型使用了双路 Whisper Encoder 进行语音编码,8层 RVQ 量化。
训练分为两个阶段,采用多任务学习策略:
阶段一:语义对齐 + 声学保持训练。ASR任务和重建任务,让编码器在编码语义信息的同时保留粗粒度的声学信息。
阶段二:生成式声学细化。固定住编码器和量化层部分,只训练解码器部分。通过重建损失和 GAN 损失,利用生成式模型的能力补充细粒度声学信息。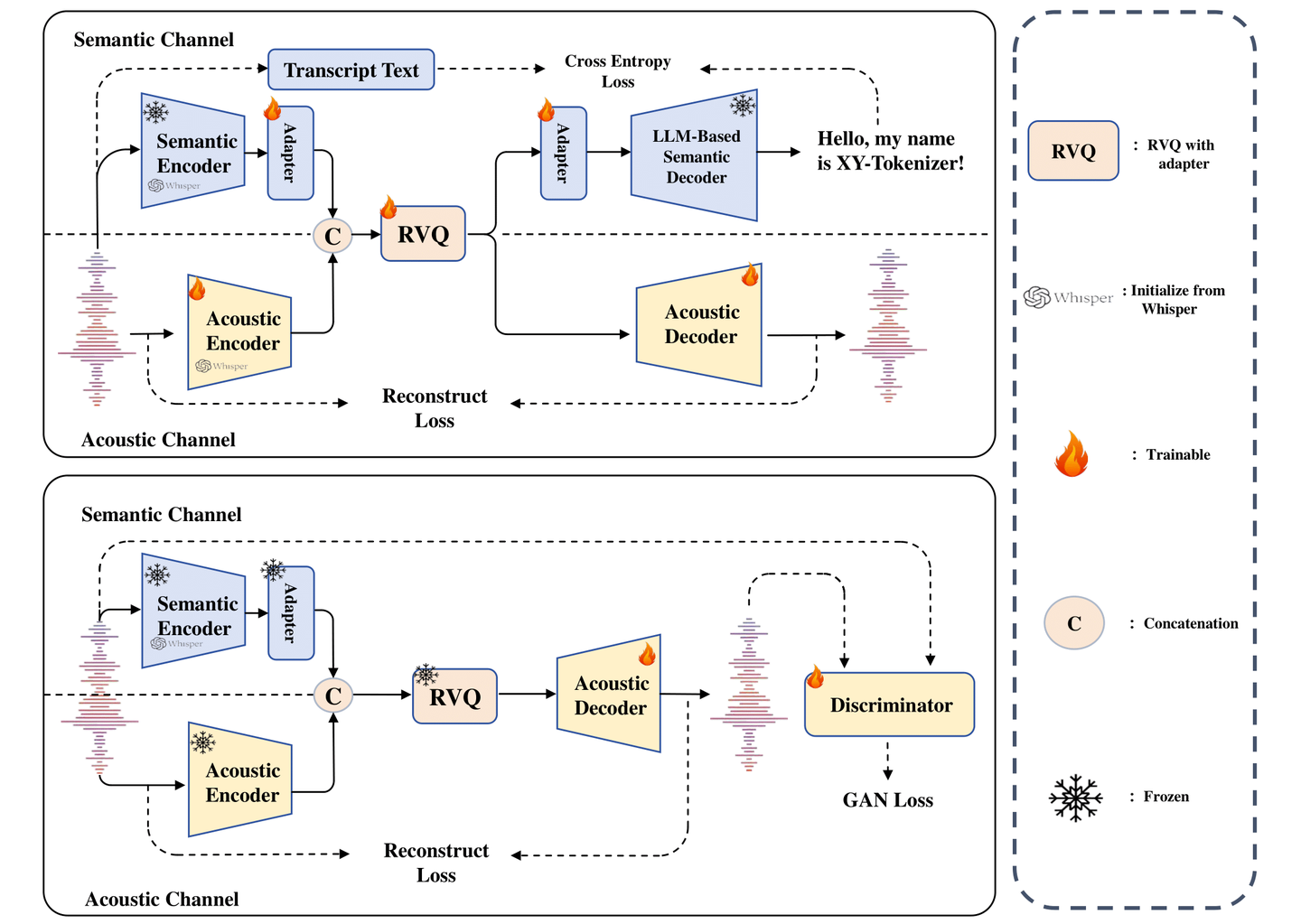
效果
- 使用 10 万小时转录语音数据进行基础训练,确保语义编码质量;
- 引入 50 万小时无标注语音数据 进行扩展训练,有效增强模型对复杂对话语音及多场景语音的建模能力;
- 支持最长 960 秒语音输入,在超长语音建模方面表现出色。
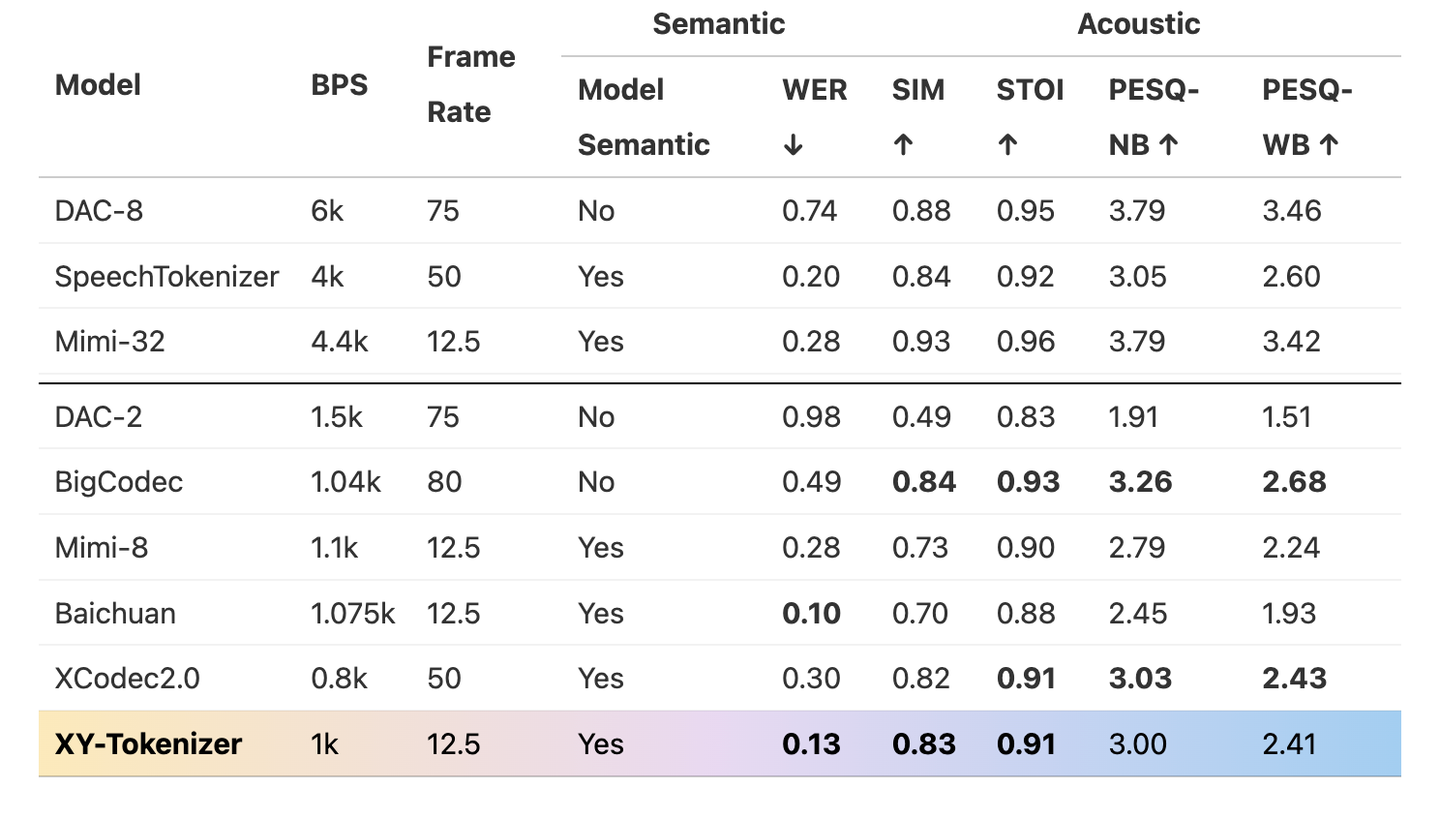
小结
XY-Tokenizer 在低比特率(1 Kbps)和低帧率(12.5 Hz)下,同时实现了高质量的语义表示和声学重建能力。其两阶段训练策略和海量多样化数据的支持,使其在真实对话音频生成与理解任务中具有较高潜力。
higgs-audio-v2-tokenizer (2025.07) 


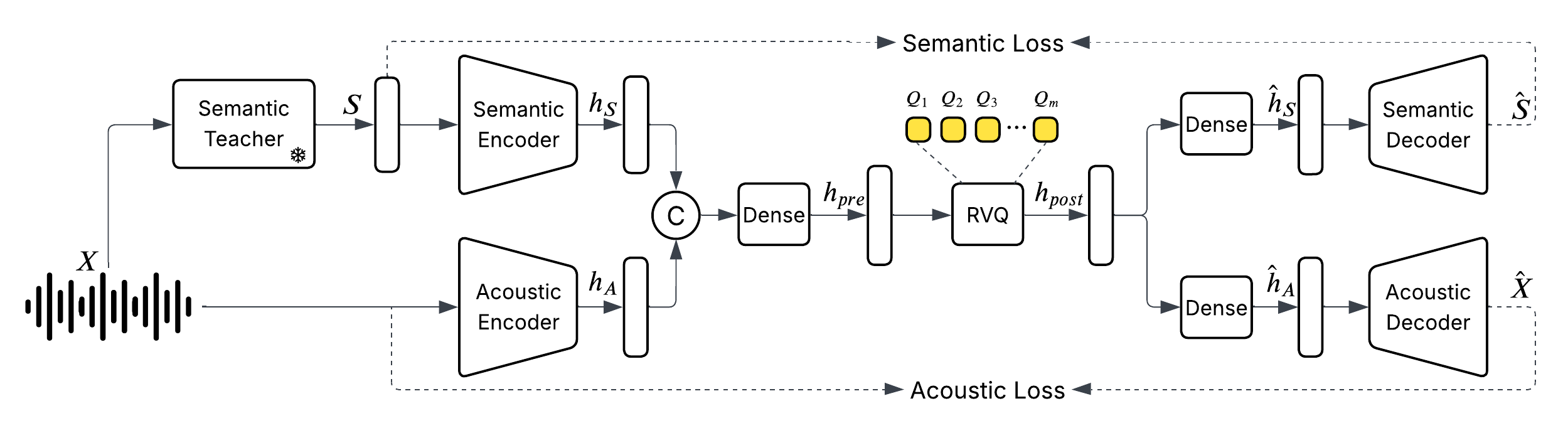
higgs-audio-v2-tokenizer是李沐老师创业公司BosonAI于2025年7月发布的开源Audio Codec,具备极低帧率、适合多模态大模型建模。
模型架构
- 语义-声学分离融合建模:分别对 语义信息(Semantic) 和 声学信息(Acoustic) 进行独立建模,然后在量化前进行融合,使得 token 表达同时具备语义可控性与音频细节;
- Residual Vector Quantization(RVQ):延续了业界主流的离散化方式,保证生成质量与 token 稠密度的平衡;
- 极低帧率(25fps):极大减少了 token 数量,更适合接入 LLM 进行多模态建模和语音生成任务。
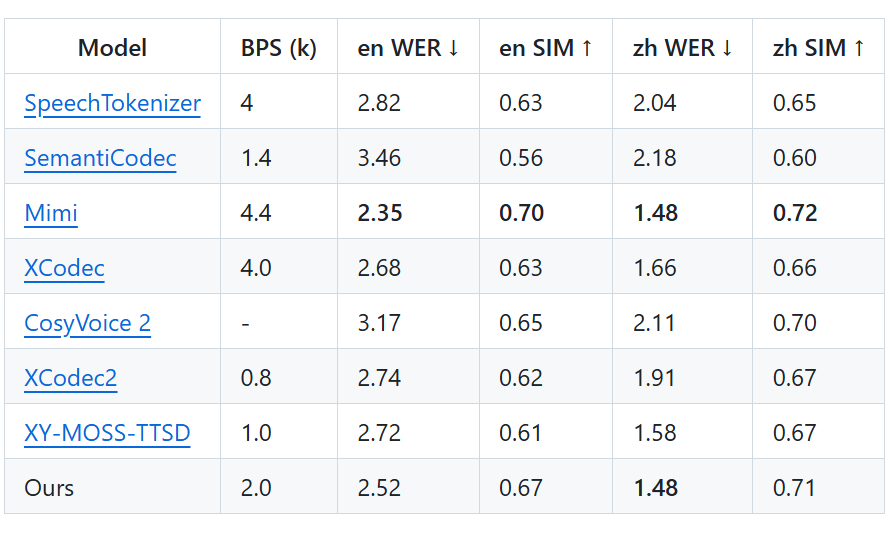
效果
语义效果评估采用了(Seed-TTS eval)作为评测集,在更低比特率(BitRate)设定下,模型在语义一致性方面可与 Mimi 相媲美,表现出良好的生成对齐能力。
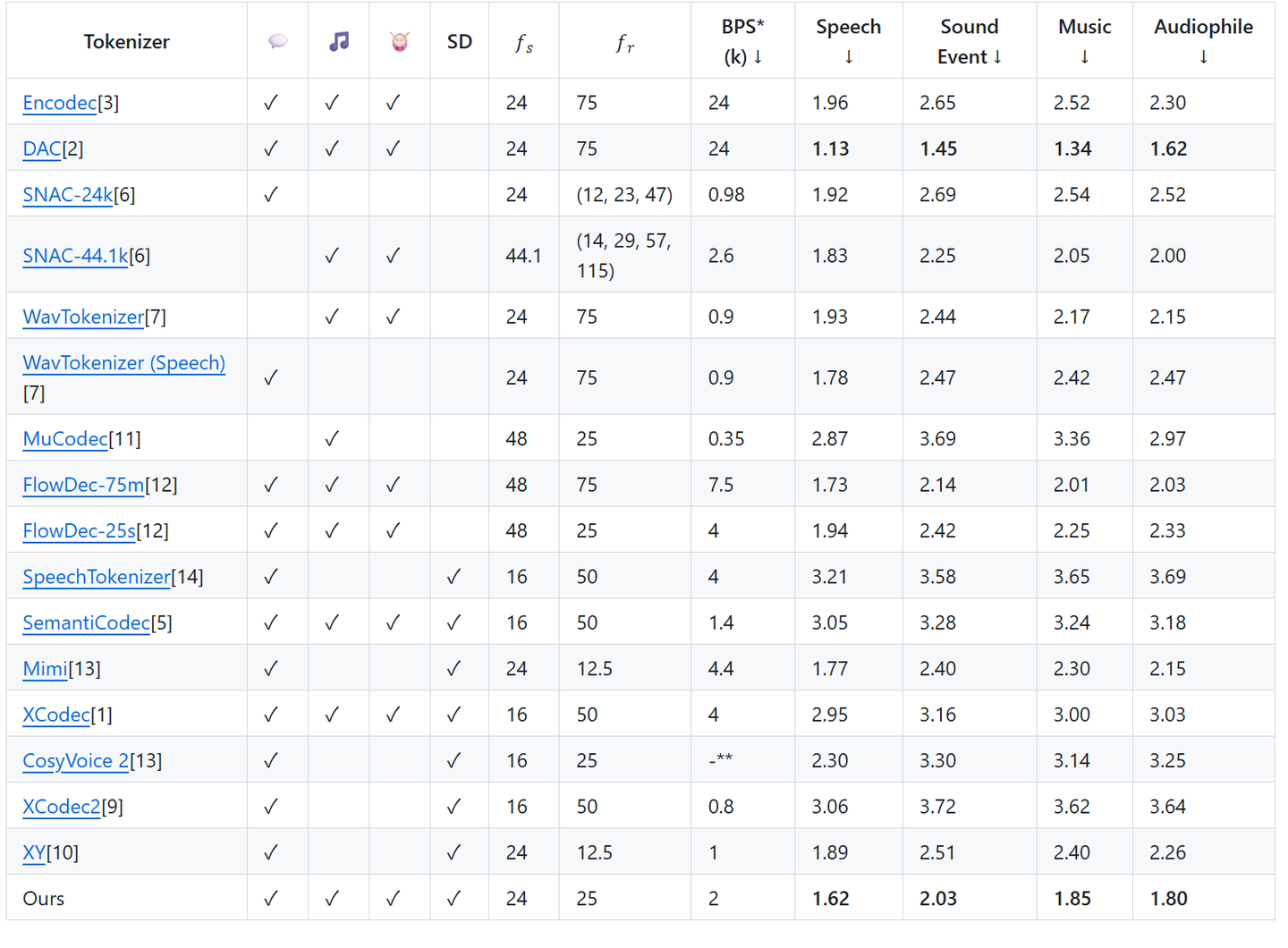
在声学效果评估方面,采用了 STFT metric 作为评估指标。评测集由 4 个子集组成: DAPS(Speech)、MUSDB(Music)、AudioSet(Sound Event)以及 Audiophile(高保真音乐)。在多种类型音频上,模型在细节保留与主观感知质量上均达到高水平。
小结
higgs-audio-v2-tokenizer 是一款专为语音大模型设计的高效 Audio Tokenizer,其创新的语义-声学分离融合机制和极低帧率设计,显著降低了建模成本,同时保持了出色的语音还原质量。它不仅为 Higgs Audio 提供Tokenizer支持,也为语音大模型的Tokenizer提供了有价值的借鉴。
总结
Audio Tokenizer成为大模型的关键技术
随着大模型能力的不断延展,多模态甚至全模态的大模型正在深刻变革语音技术的传统范式。语音任务正在从以模块化、定制化为主的架构,逐步转向由统一大模型驱动的端到端解决方案。
单点的语音能力也在向大模型方向演进,以语音识别为例,OpenAI 的 Whisper 模型在通用场景下的表现已显著优于传统的定制小模型,凭借大数据预训练和强鲁棒性,在多语言、多口音、嘈杂环境下依然具备出色性能。这类“预训练+指令微调”的语音大模型方案,正逐渐成为语音识别的新主流, 具体可以参考:OpenAI Whisper 新一代语音技术(更新至v3-turbo)
大模型已不再局限于感知层的“识别”,而是逐步向“理解”和“生成”扩展。语音模态和大模型深度融合,也已经有很多相关工作了,虽然在端到端语音交互能力方面和传统级联方案略有逊色,但是在语音理解和生成能力方面已经远超过传统的单一能力模型,具体可以参考语音大模型概述:语音大模型概述
尽管当前端到端语音交互模型在一些低资源场景下仍存在响应速度或精度的差距,但其多任务泛化能力和统一建模框架的优势,已在多个应用方向展现出巨大的潜力。
展望未来,音频模态与大模型的深度融合已成为语音领域的技术主旋律,而 Audio Tokenizer 的演进,则是这一趋势背后的关键基石。
Audio Tokenizer的演进趋势
- 极致压缩、更低的TokenRate:开篇提到的挑战,语音相比文本有更长的序列,即便目前较低的tokenrate,达到25token/s,相比于文本的大概3-4token/s,仍然有6倍的差异。继续把语音压缩到更低的TokenRate,有助于语音与文本的模态融合与对齐。
- 全面的信息表示:在极致压缩下,保留语义信息、副语言信息、声学信息等,才能实现后续的音频相关各项任务。
参考文献
- Audio Tokenization: An Overview
- How Should We Extract Discrete Audio Tokens from Self-Supervised Models?
- Vector Quantization in PyTorch
- Residual Vector Quantization: An exploration of the heart of neural audio codecs