目前从事语音识别、语音合成、多模态大模型工作,追求我的North Star:希望在语音领域做出一点成绩,让这个世界因为我,哪怕而有一点点的不同。
基本信息
- 姓名:shuaijiang
- 研究方向: 语音识别、语音合成、多模态语音大模型
- 职业追求:语音改变世界
- Email:zhaoshuaijiang8(at)gmail.com
- 个人主页:http://www.zhaoshuaijiang.com
- Github:https://github.com/shuaijiang/
- Resume: shuaijiang’s resume
教育经历
- 2013-2016,北京大学,言语听觉研究中心
- 2009-2013,北京邮电大学,智能科学与技术
项目经历
语音/语言大模型(2023~2025)
- 语音大模型语音文本对齐研究 2025.03-2025.05(EMNLP2025) [pdf]:
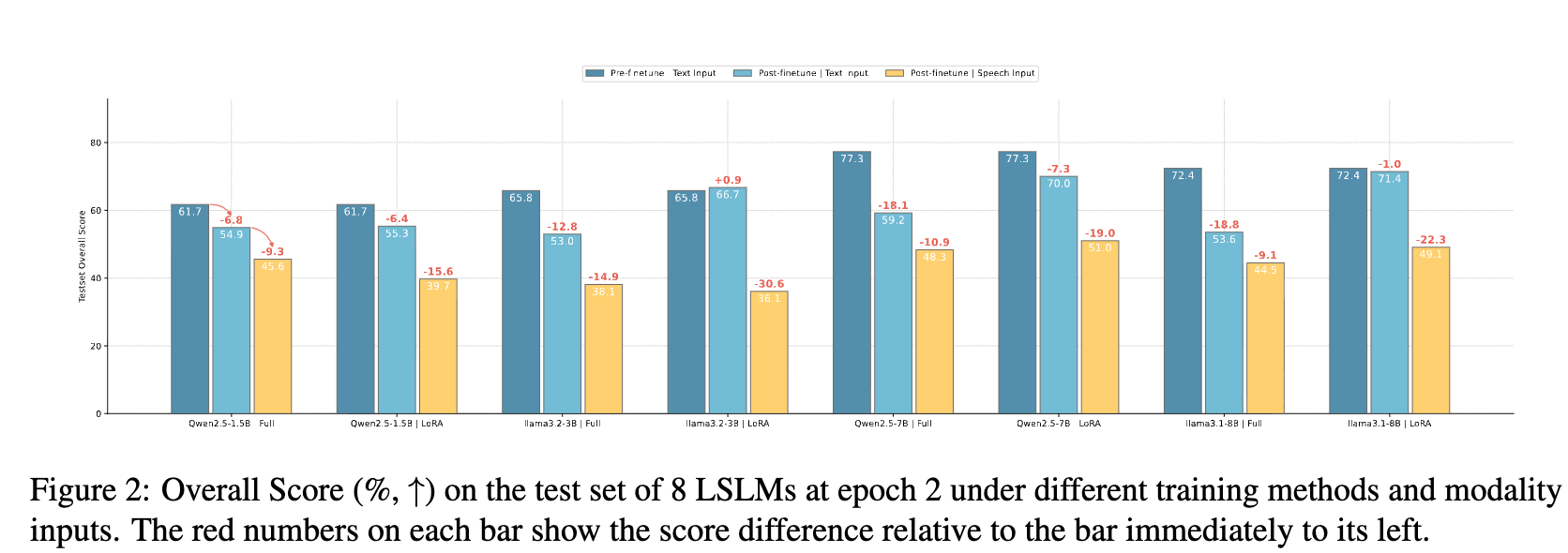
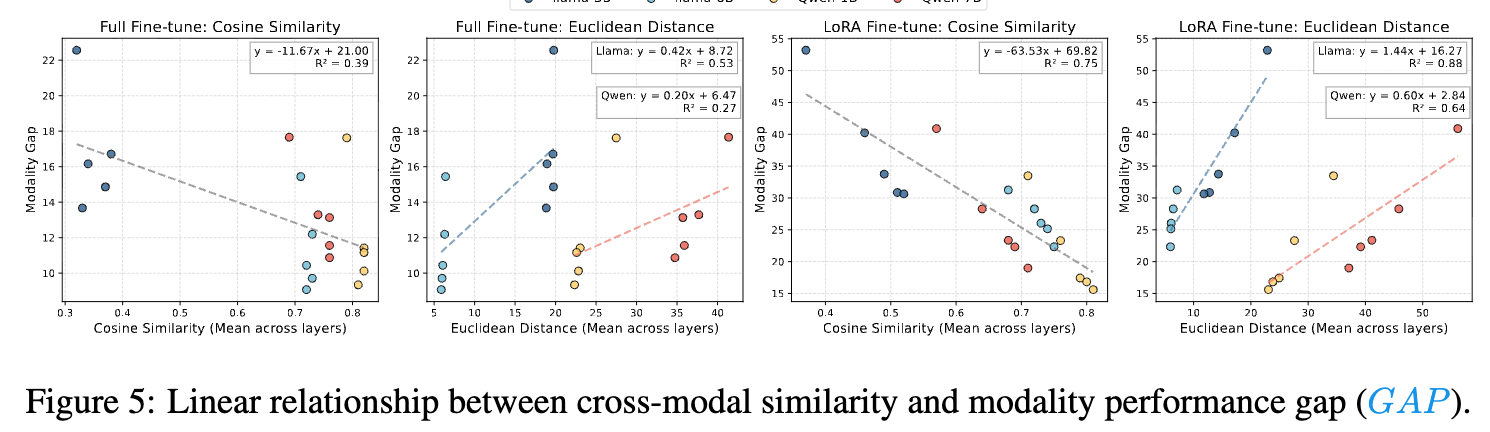
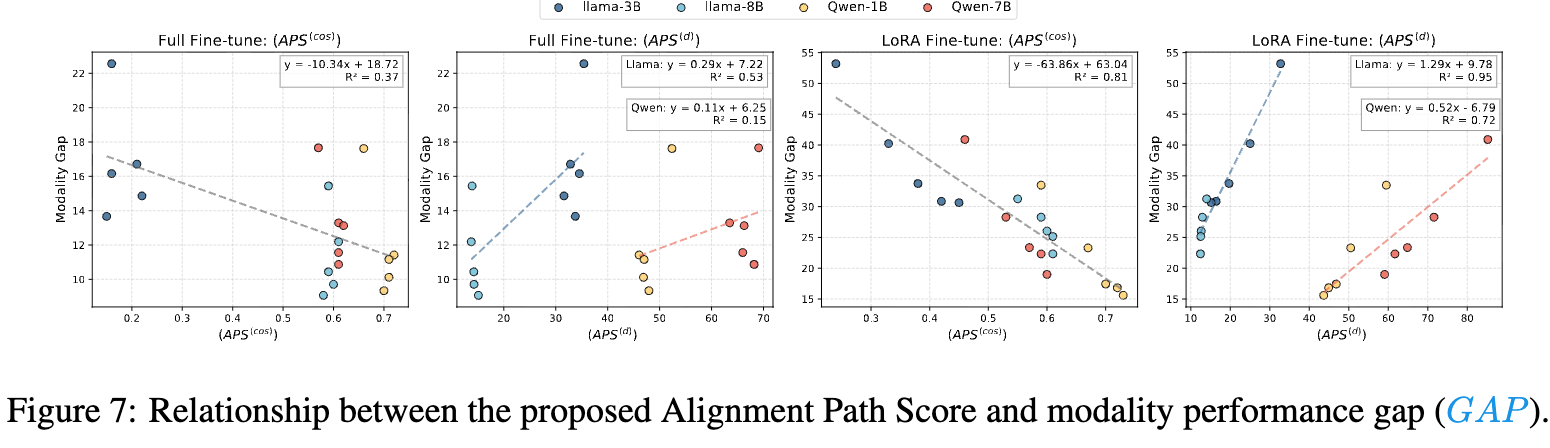
本研究系统性地探究了主流语音大模型普遍存在的模态鸿沟”Modality Gap”现象。
分别从粗粒度和细粒度采用不同语音-文本模态相似度量指标实现相关性分析。
通过跨模态干涉实验验证了相关性,为进一步研究缓解模态鸿沟提供了方向。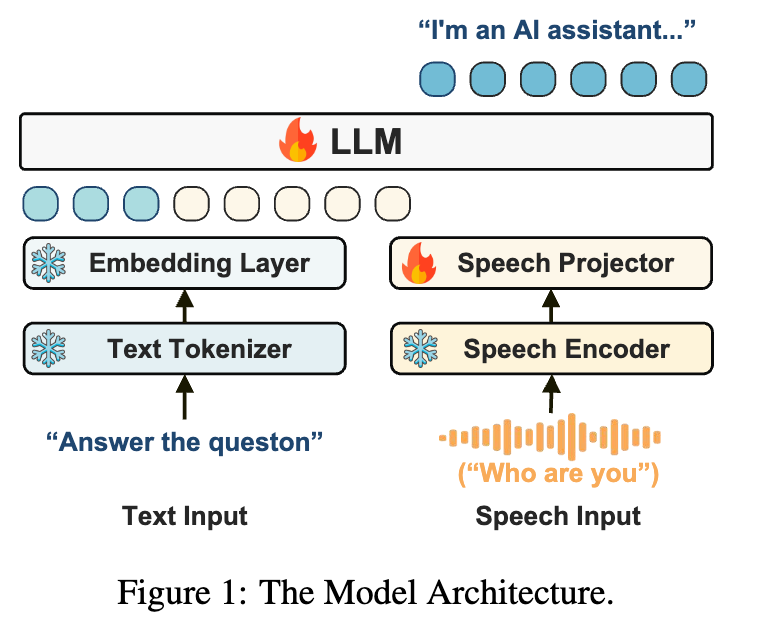
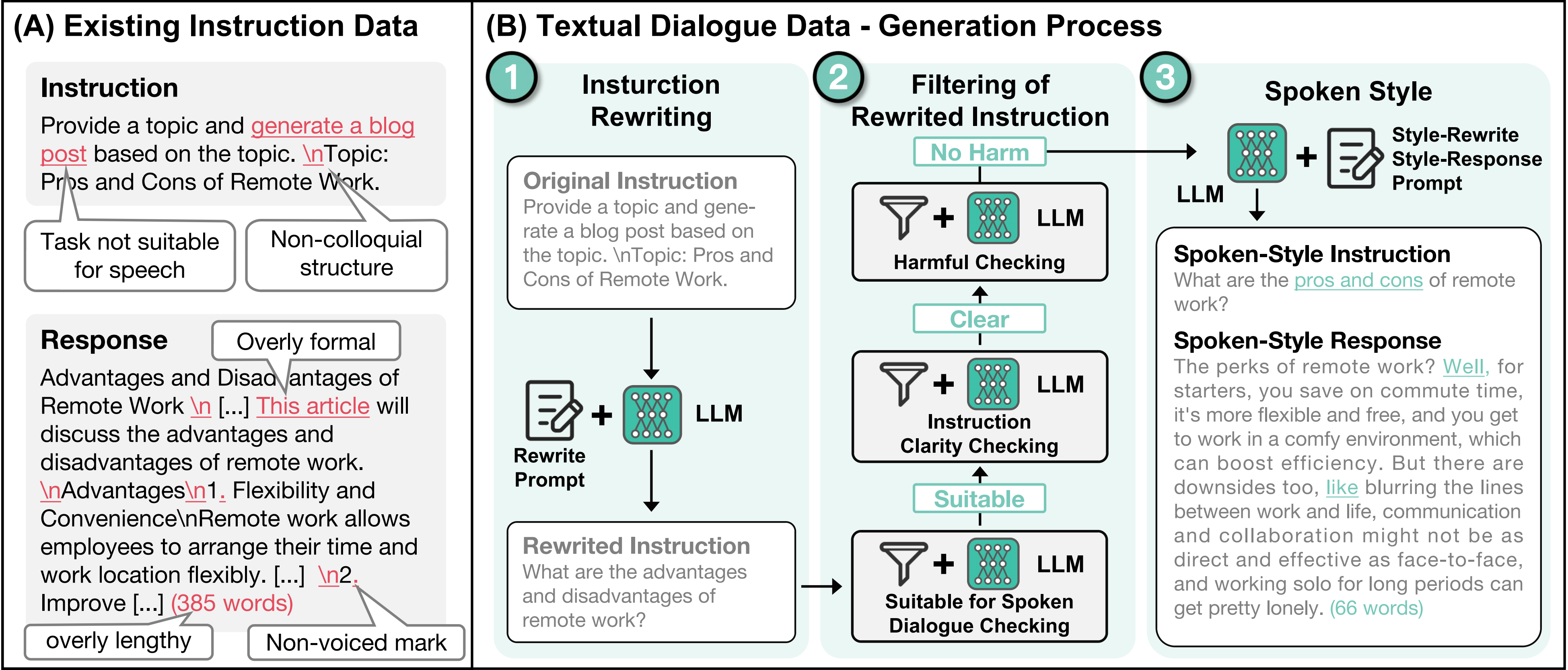
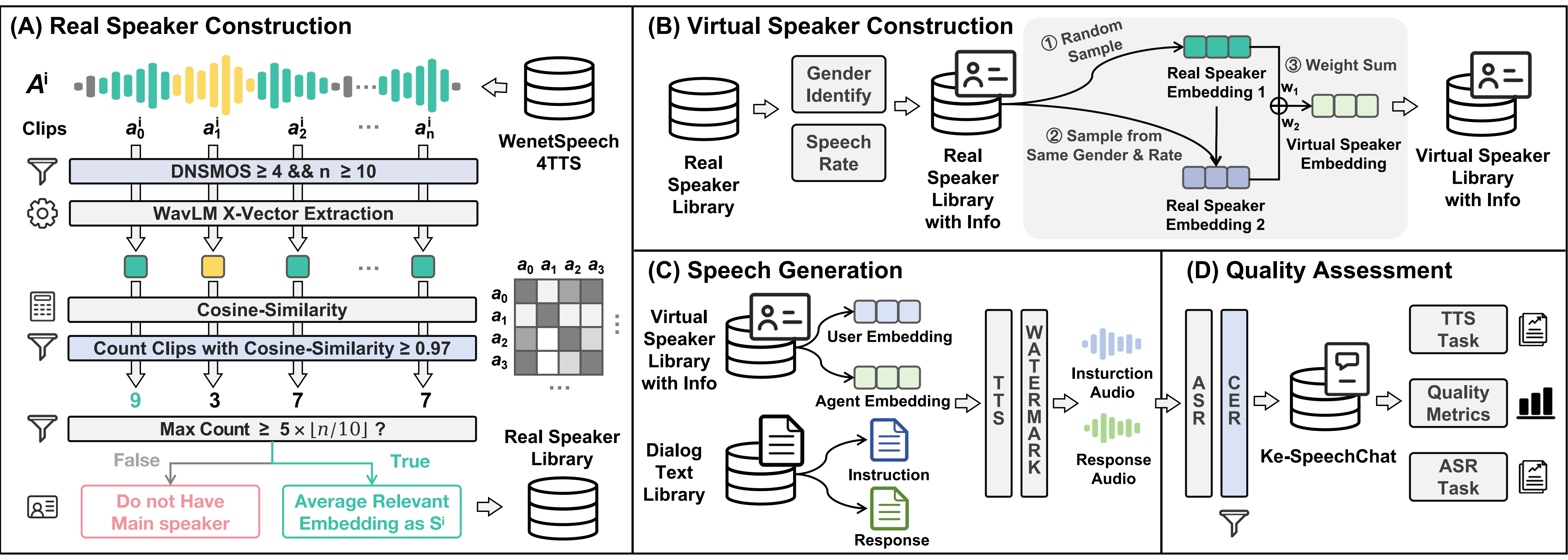
语音大模型KE-Omni & 语音对话数据Ke-SpeechChat 2024.08-2025.03 [arXiv|demo]: 搭建端到端语音大模型,强大语音理解与生成能力、超低延迟,带来交互体验跨越提升。
基于6万小时高质量合成对话数据,构建语音大模型,实现流式语音对话。
解决对话数据不足问题,构建语音对话生产与质检系统,产出10万小时高质量对话数据。
自研语音大模型Ke-Omni,在对话理解榜单VoiceBench上超越Qwen2-Audio。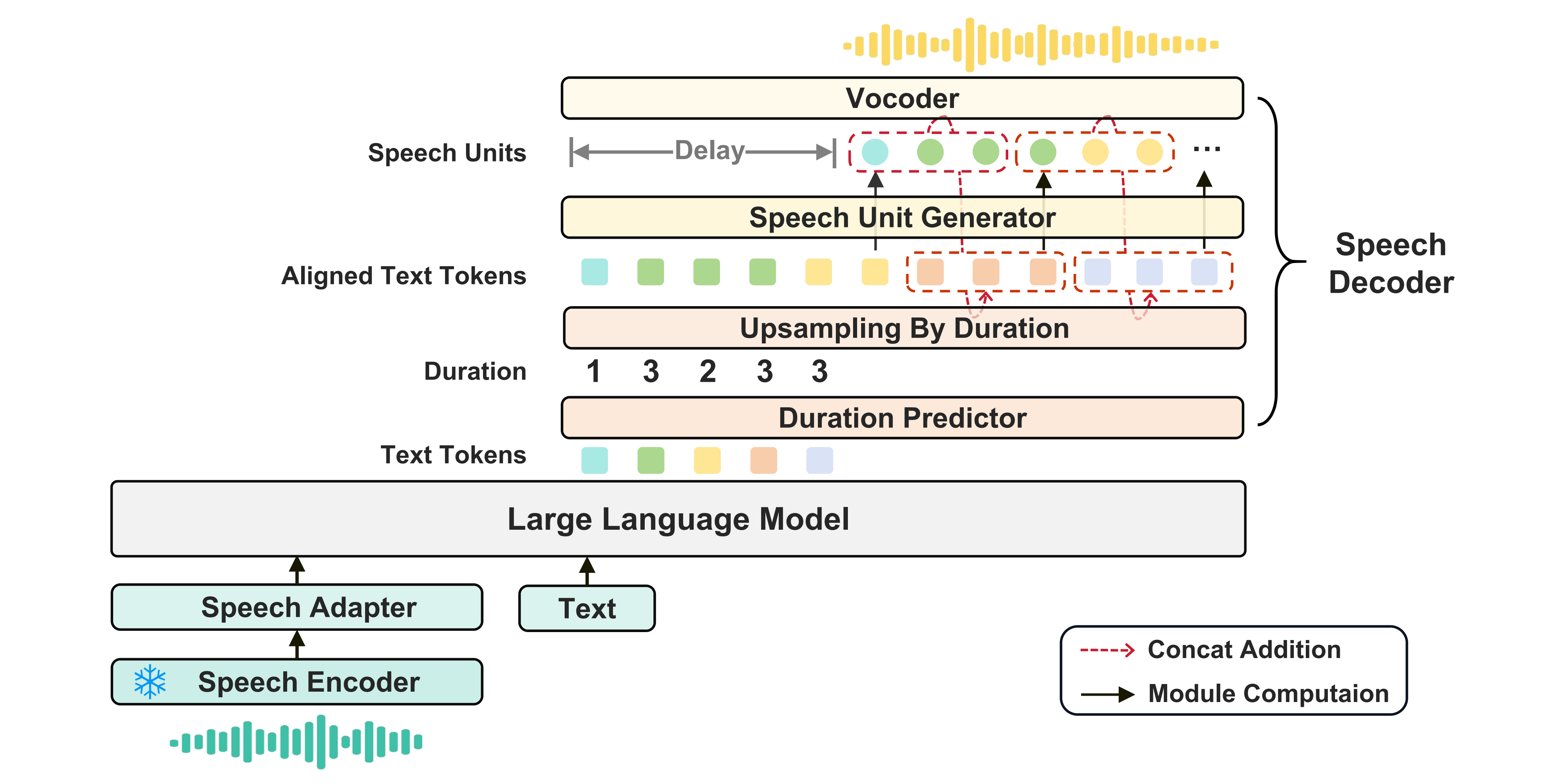
音频推理大模型Ke-Omni-R 2025.03-2025.04 [Github]:
构建音频推理模型,通过强化学习引入深度思考过程,提升复杂任务的理解和推理能力。
基于Qwen2.5-Omni,GRPO强化学习训练,在音频推理榜单MMAU上达到SOTA。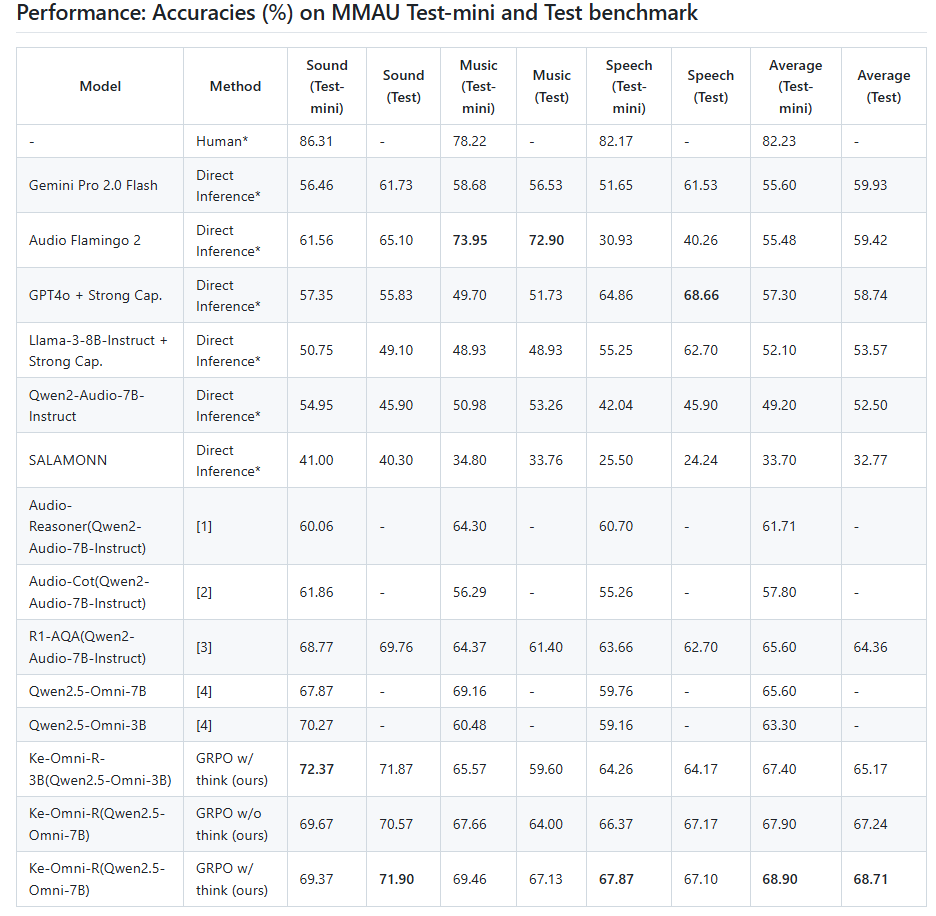
大模型数据能力构建 2023-2024 [技术报告]: 搭建贝壳领域大语言模型的数据平台,支撑居住领域大模型的训练。
构建了数据读取、去重、清洗、过滤、挑选混合等相关能力,提升LLM效果。参加2024年Better-mixture算法大赛,荣获季军。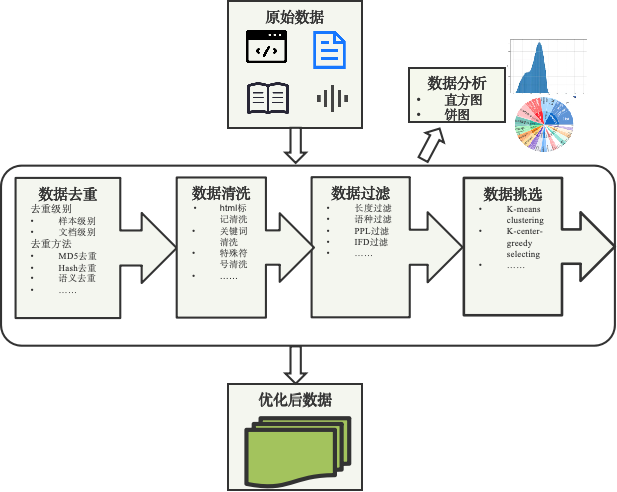
大模型评测能力构建 2023-2024: 搭建贝壳领域大语言模型的评测平台,支撑居住领域大模型的评测。
构建了涵盖通用能力、业务场景的评测体系,支持多种模型接入方式、多种评测指标,有效支撑模型的训练过程和落地指导。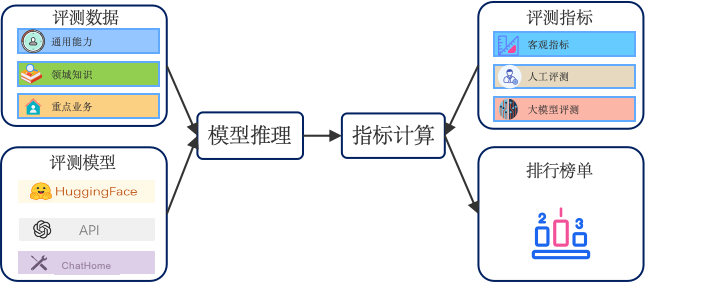
BelleWhisper语音识别 2023-2024 [开源模型belle-whisper-large-v3-zh-punct & Belle-whisper-large-v3-turbo-zh]:
打造领域泛化统一的语音识别,取代深度定制,更多模型参数、数据,提升精度和鲁棒性。
基于Whisper优化中文语音识别能力,统一了不同采样率、离线在线识别、不同业务场景,并在业务上落地应用,字错误率相对下降约20%。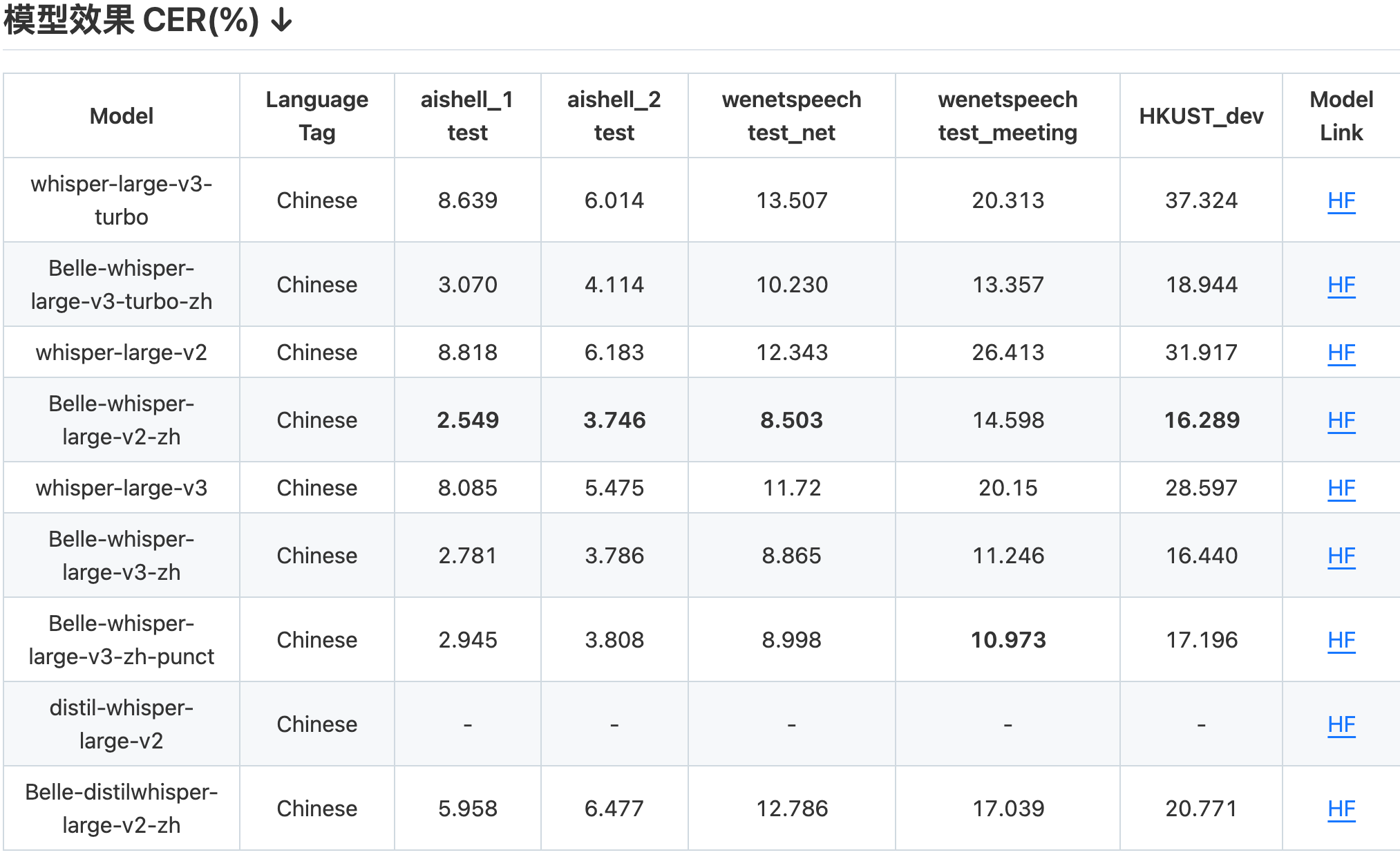
语音识别(2018~2023)
智能家居语音交互 2020.12-2022.04:
打造完成贝壳“小海智家”智能家居产品。从零搭建智能家居语音识别能力,针对环境中的噪声、混响等复杂声学情况,针对高频命令控制的query,分别提出解决方案,实现高精度、低延迟的语音识别。
为解决噪声混响问题,语音叠加噪声、混响模拟真实环境,识别精度由87%提升到92%。
为解决领域不匹配问题,通过语言模型自适应训练,识别精度进一步提升至94%。车载语音识别与交互 2018.7-2020.04:实现滴滴全程录音语音识别能力,保障出行安全。
行程中录音语音识别是保障出行安全的基础,面临环境复杂、远场、无数据等问题。
基于LAS框架构建鲁棒语音识别,数据增强扩充(加车噪、加混响),提升模型鲁棒性。
研发半监督训练框架,筛选线上大量弱标签数据,对模型快速优化,识别精度提升5%。
行程中录音语音识别率从50%提升到84%,1个月内落地可用,并实现100%全覆盖。
基于端到端方法的中英文夹杂(CODE-SWITCHING)语音识别 2017.12-2018.10 arXiv:
普遍存在的中英文夹杂现象给语音识别带来很大挑战,传统级联方案系统复杂、精度低。
基于Attention的端到端语音识别框架,端到端实现中英文夹杂的语音识别。
探究了建模单元(char、subword),解码策略,多任务学习(联合CTC、融合语种信息)。
在SEAME数据上达到SOTA,MER 34%。应用到多方言混合语音识别,整体提升10%。端到端语音识别研究与落地 2017.11-2018.5:
对于CTC、Attention这两类端到端的方法,分别对比了音素、音节、字不同尺度建模单元的性能;
实验发现了一些有价值的结果,对不同条件下的语音识别应用有借鉴意义并发表论文。
基于Transformer框架搭建端到端的语音识别,将多任务学习应用到模型训练,联合Attention与CTC,提升系统训练的鲁棒性,系统达到了较高的性能;并且部署上线,落地到业务。
语音合成(2013~2017)
基于神经网络的语音合成及在明星音合成中的应用:实现多个百度地图导航播报明星音。
在大规模语音数据条件下(几十甚至上百小时数据),完成神经网络模型训练。
通过模型自适应与数据平衡,0.5小时极小量明星音实现了高质量明星音合成MOS 3.8。
明星音在百度地图导航上广泛应用,数量超过竞品,并得到地图部门的高度认可。基于深层神经网络的语音合成:为解决GMM趋向均值导致的过平滑问题,在语音合成声学建模中引入循环神经网络。利用深层循环神经网络实现从文本特征到语音声学特征的映射,取代了传统基于HMM的语音合成架构中的决策树和高斯模型,大幅提高了声学模型性能。探讨不同层级文本特征对声学建模的影响;引入韵律信息,进一步提高声学模型的性能。基于深层循环神经网络实现语音合成,声学特征误差由基线系统的5.8 dB降低到5.0 dB。
基于MGE的语音合成: 基于HMM的参数语音合成中,将模型训练准则由最大似然准则(MLE) 改为最小生成误差准则(MGE),提高了声学模型性能。
开源项目
- Ke-Omni-R: 语音推理大模型项目,基于GRPO强化学习增强模型推理能力。 Github
- Whisper-Finetune:基于Whisper的语音识别项目 Github
- Athena:基于Transform的端到端语音识别项目 Github
- Belle:语音/语言大模型项目 Github
论文发表
- Understanding the Modality Gap: An Empirical Study on the Speech-Text
Alignment Mechanism of Large Speech Language Models.EMNLP2025 - SARI: Structured Audio Reasoning via Curriculum-Guided Reinforcement Learning.2025. arXiv
- Advancing Speech Language Models by Scaling Supervised Fine-Tuning with Over 60,000 Hours of Synthetic Speech Dialogue Data.2024. arXiv
- Technical Report: Competition Solution For BetterMixture[J], 2024. pdf
- ChatHome: Development and Evaluation of a Domain-Specific Language Model for Home Renovation. 2023. pdf
- KeSpeech: An Open Source Speech Dataset of Mandarin and Its Eight Subdialects[J]. 2021. pdf
- Gigaspeech: An evolving, multi-domain asr corpus with 10,000 hours of transcribed audio[J]. arXiv preprint arXiv:2106.06909, 2021. pdf
- DiDiSpeech: A Large Scale Mandarin Speech Corpus[J]. arXiv preprint arXiv:2010.09275, 2020. pdf
- Towards end-to-end code-switching speech recognition[J]. arXiv preprint arXiv:1810.13091, 2018. pdf
- Comparable study of modeling units for end-to-end mandarin speech recognition[C]//2018 11th International Symposium on Chinese Spoken Language Processing (ISCSLP). IEEE, 2018: 369-373.pdf
我的公开课
兴趣爱好
- 参加并完成了2014年的北京马拉松

赞赏
- 我的成长离不开大家的支持
- 扫一扫,谢谢!
