基于HMM的参数式语音合成
背景介绍
20世纪90年代中期,参数式语音合成得到人们的关注;基于HMM的参数式语音合成快速发展,并成为主流。
隐马尔科夫模型(Hidden Markov Models, HMM)
20世纪60年代末,Baum在理论上给出了关于隐马尔科夫模型的数学推理。一直到80年代,才有人用来解释语音信号的产生过程。经过30多年的发展,HMM已经被广泛应用到语音识别、说话人识别和语音合成等领域,并取得了巨大的成功。
基于HMM的参数式语音合成
系统框图
下图是基于HMM的参数式语音合成系统的框图。包括两个阶段:训练阶段,合成阶段。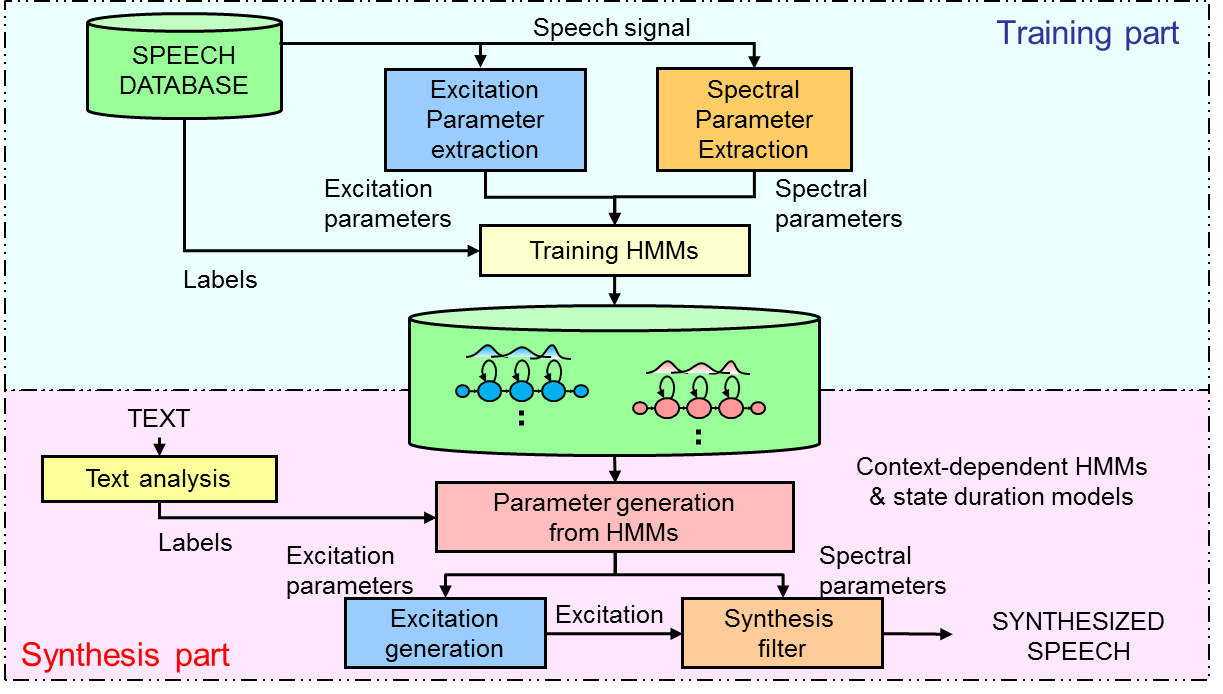
训练阶段
首先从训练语音数据库中提取特征参数,然后训练上下文相关的HMM模型,并且依据上下文相关的问题集利用决策树对模型聚类,最后训练得到模型。
合成阶段
先将输入文本经过文本前端分析得到上下文标注,然后根据相应的决策树为上下文标注生成合适的HMM状态序列,并利用时长模型预测出相应的状态时长,最后通过最大似然准则约束下的参数生成算法得到谱参数和基频,并采用合适的参数合成器生成语音。
优点
- 可以方便地实现声音特点、说话方式和感情的转换。这也是参数式语音合成的主要优点。
- 声学空间的有效覆盖。相比于基于单元挑选的波形拼接式语音合成,依赖于单元库的大小;参数式语音合成利用统计方法生成语音,从而比基于单元挑选的语音合成有更大的声学空间。
- 多语言支持。基于单元挑选的波形拼接式语音合成,对于每种语言都需要相应的单元库。参数式语音合成对于不同的语言,只要相应的改变训练数据,并进行训练即可。
缺点
- 声码器。基于HMM的参数式语音合成利用梅尔倒谱声码器,听起来会比较闷(buzzy)
- 声学建模的准确性。
- 过拟合问题。相比于自然语音,合成的语音听起来会明显地沉闷(muffled),这主要就是因为生成的语音参数总是过拟合的。在建模过程中语音的细节特征被忽略了,在合成过程中不能被恢复。
参考文献
- YoshimuraÝ T, TokudaÝ K, MasukoÝÝ T, et al. Simultaneous modeling of spectrum, pitch and duration in HMM-based speech synthesis[J]. 1999.
- 于延锁.语音合成中韵律建模方法研究[D]. Ph.D. thesis, 北京大学, 2013
- Zen H, Tokuda K, Black A W. Statistical parametric speech synthesis[J]. Speech Communication, 2009, 51(11): 1039-1064.
基于HMM的参数式语音合成
http://zhaoshuaijiang.com/2014/04/01/hmm_based_speech_synthesis/