端到端语音识别基础入门
传统与端到端语音识别框架
传统的语音识别框架[Automatic Speech Recognition]
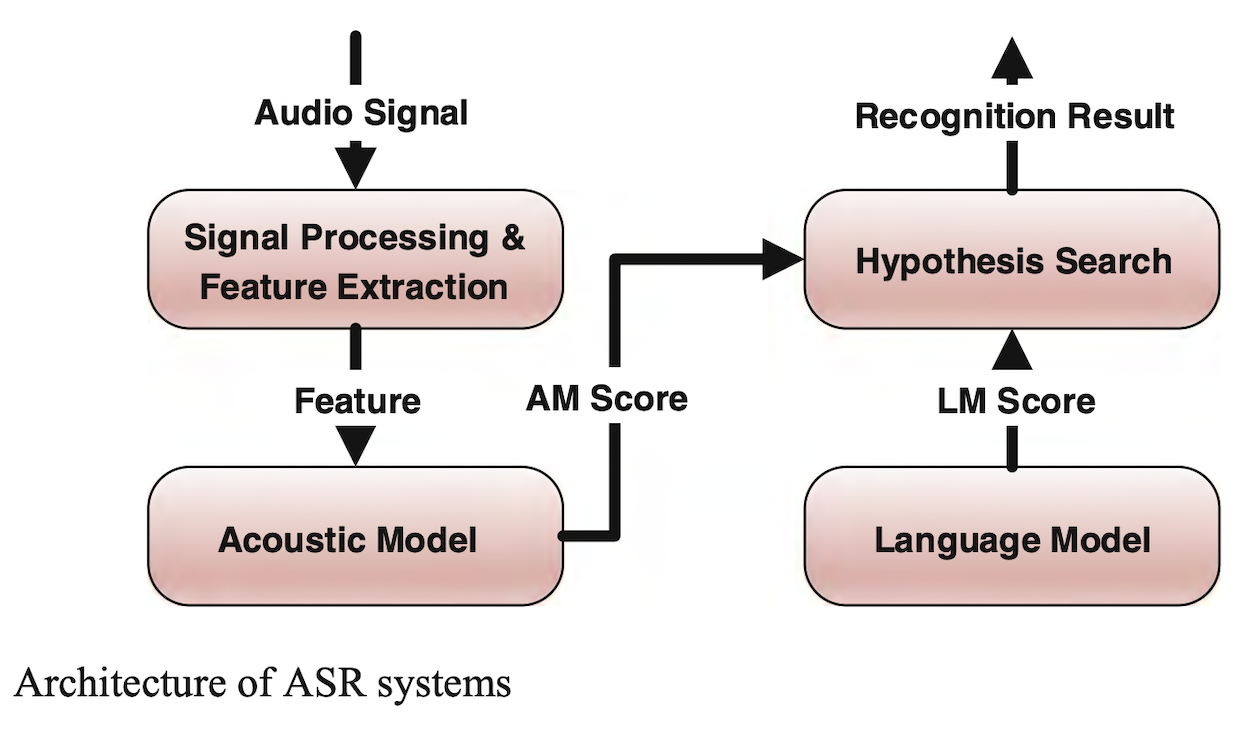
端到端语音识别框架[Machine Learning Yearning]

基础课程
课程网址:http://www.speech.zone/courses/
这是爱丁堡大学的一名很有名气的语音方向的教授Simon King将他的授课内容分享出来的网站,里面的内容都是关于语音,丰富而且很清晰明了,即便有语音基础的同学学习一边也会受益匪浅。
如果没有语音基础,建议从语音处理基础开始课程,了解语音信号、音素等,然后再进一步到语音识别,包括特征工作,例如MFCC特征、filterBank特征,以及具体的算法。
传统语音识别技术(2009年)
这一时期的语音识别主要是基于统计模型建模,其中隐马尔可夫模型大获成功。
- An Overview of Modern Speech Recognition[An Overview of Modern Speech Recognition]
- 虽然名为’modern’,但是现在已经确实为’conventional’
- 详细介绍了传统语音识别框架中的声学模型、语言模型、解码,以及语音识别的应用。
端到端语音识别技术
目前端到端语音识别主要有基于CTC的方法、基于Attention的方法,以及结合二者的多任务学习方法。
End-to-end ASR Tutorial
- Interspeech 2018_ Tutorial E2E Speech Recognition[pdf]
- 这是Google的关于端到端语音识别的tutorial,可以从宏观上观察端到端语音识别的发展,以及不同方法的优劣。
CTC
- Connectionist Temporal Classification Labelling Unsegmented Sequence Data with Recurrent Neural Networks[pdf]
- deep speech [pdf]
- deep speech2[pdf]
- Supervised Sequence Labelling with Recurrent Neural Networks[pdf] 介绍CTC部分主要是在第7章,需要重点看下。
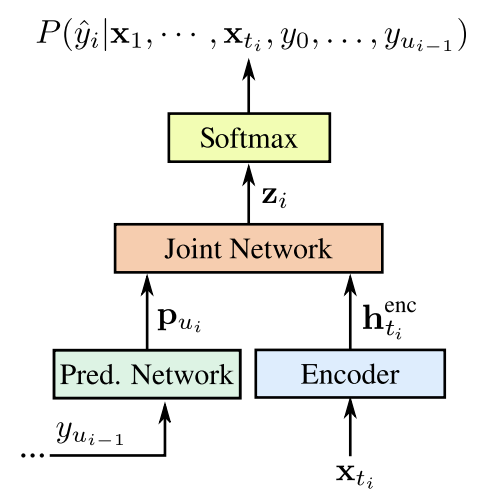
RNN-T
RNN-T全称是Recurrent Neural Network Transducer,是在CTC的基础上改进的。
CTC的缺点是它没有考虑输出之间的依赖,RNN-T则在CTC模型的Encoder基础上,又加入了一个将之前时刻的输出作为输入的RNN(Prediction Network),
将Prediction Network输出与Encoder的输出共同作为一个joint network的输入,得到输出logits通过softmax layer得到最终输出的概率。
- Sequence Transduction with Recurrent Neural Networks[pdf]
Attention
- Attention-Based Models for Speech Recognition[pdf]
- Listen, Attend and Spell[pdf] 这一篇算是Attention开启之作。
Joint CTC/Attention
- ESPnet 实现了Hybrid CTC/attention based end-to-end ASR [github]
- JOINT CTC-ATTENTION BASED END-TO-END SPEECH RECOGNITION USING MULTI-TASK LEARNING[pdf]
- Hybrid CTC-Attention Architecture for End-to-End Speech Recognition[pdf]
Conformer
- Conformer: Convolution-augmented Transformer for Speech Recognition[pdf]
端到端语音识别基础入门
http://zhaoshuaijiang.com/2019/02/15/end-to-end-asr/